関数電卓プログラミングの世界
この記事は、上智大学エレラボAdvent Calendar第1日目の記事です。 qiita.com
1日目ということで本来なら基調講演的なものをすべきなのかもしれませんが、一度もサークルとしての活動に参加したことがない人間にそんなもん書けるはずがありませんね。なので私個人の趣味の話をします。
私は「関数電卓でプログラミングをすること」が好きです。 しかしこの話を人にすると「関数電卓でプログラミングをするとは一体どういうことなのか」「関数電卓で一体何ができるのか」について不思議に思われることが多いので、今回はこの2つの話題について書きたいと思います。
関数電卓とは
理工学系の学生には馴染み深いと思いますが、関数電卓とは普通の四則演算に加え、 三角関数・指数関数・対数関数などに代表される高度な計算が可能な電卓のことです。

一般的な関数電卓の一例
しかし関数電卓というのはこの写真のような種類の物だけではありません。 上位互換として複雑な計算を自動で行えるようにプログラミング機能を搭載した「プログラム電卓」や、 さらにその上位互換として、関数のグラフを表示する機能などが付いた「グラフ電卓」なんて代物も存在します (以下、こういった普通の関数電卓よりハイスペックな機種をまとめて「高機能電卓」と呼称することにします)。 私は数ある関数電卓の中でも、こうした高機能電卓でプログラミングをして遊ぶのが好きなんです。

一般的な高機能電卓の例
注釈
「関数電卓」や、よりハイスペックな「プログラム電卓」「グラフ電卓」の定義についてはマニアの間で議論の対象になっていますが、 この記事では実際に販売されている機種の特徴を鑑みて
と定義することにします。
本来の字義通りならば
- プログラム電卓 := プログラミング機能がある電卓
- グラフ電卓 := グラフ描画機能がある電卓
- "(グラフ電卓 ∩ 関数電卓 ≠ ∅) ∧ (プログラム電卓 ∩ 関数電卓 ≠ ∅) ∧ (グラフ電卓 ∩ プログラム電卓 ≠ ∅)" の関係が成立
とすべきなのは確かです。
しかし現実に「グラフ電卓」として販売されている機種はほとんどが両者の積集合であり、
かつメーカー側はある機種が両者の機能を兼ね備えている場合「グラフ電卓」の呼称を優先する傾向があるため、
グラフ電卓はプログラム電卓の部分集合と見なして問題ないと私は考えています。
カシオなんかは「プログラム関数電卓」「グラフ関数電卓」として、あくまで関数電卓の上位機種として売り出していますね。
実際の機種
さて、高機能電卓が具体的にどのようなものなのか、実例とそのスペックを挙げながら探ってみましょう。

HP 50g(画像出典:Wikimedia Commons)
{kind=link}
これはヒューレット・パッカード社製のHP50gという高機能電卓です。 既に廃盤済みのモデルですが、今でもコアなファンから根強い支持を得ている製品でもあります。 以下、スペックを見てみましょう。
はい、ぶっちゃけ超絶ちゃっちいですね。 しかしこれは2006年に販売開始されたモデルであることに注意が必要です。 当時のマシンスペックを考えれば、PDAとしてはそこそこのスペックだったのではないでしょうか。
プログラミングの観点から見たこの機種の特徴は、低レイヤまでアクセスする方法が多様に存在することだと思います。 この機種は RPL(Reverse Polish Lisp) というForthとLispを合体させたような独自のスクリプト言語をベースに、 スタックベースのREPL環境で操作をする仕組みがデフォルトで搭載されています。 しかし公式の開発環境を導入することでアセンブリ言語や「System RPL」という独自のコンパイル言語が利用可能になり、 さらにはマニアが開発した特殊なツールを利用してC言語でコードを書くことが可能です。 またこの機種は「従来機種で使われていたCPUをARM上でエミュレートする」という特殊な手法で動作するため、 使えるアセンブリ言語が2種類存在します(従来CPUのアセンブリとARMアセンブリ)。
2つ目に移ります。

TI-Nspire CX II CAS (画像出典:Wikimedia Commons)
{kind=link}
これはテキサス・インスツルメンツ社のTI-Nspire CX II CASという機種で、2019年から販売されている最新の現行モデルです。 このスペックは以下の通りです。
- CPU:ARMコア (396MHz)
- RAM:64MB (SDRAM)
- ROM:128MB (ユーザー用NANDメモリ), 512KB (ファームウェア格納用NOR ROM)
- ディスプレイ画素数:320 x 240
HP50gの時代から10年以上が経ち、ハードウェアのスペックも向上していることが分かります。
このモデルはデフォルトでTI-BASIC, Python, Luaの3つのスクリプト言語に対応しており、 さらにマニアが開発した特殊なツールを使うことで「脱獄」を行い、C++などのコンパイル言語を用いることが出来るようになります。 この「脱獄」はいわば電卓のOSにゼロデイ攻撃を仕掛けて任意コード実行を行っているようなもので、 抜け道を塞ごうとしてOSにパッチを当てるメーカー側と電卓をハックしたいマニア側との間でいたちごっこが続いています。
脱獄ツールではありませんが、過去には別の電卓のOSについてマニアがRSAの電子署名鍵を破り、 その鍵の情報がインターネットに投稿されたことで法的措置に発展したことまであります(参考)。
3つ目に行きましょう。

(画像出典:Wikimedia Commons)
{kind=link}
これはNumworks社の高機能電卓、Numworksです(社名と同じ機種名)。2017年から発売されている機種です。 ハードウェアのバージョンはありますが、モデル名とは異なる概念なので割愛します。 このメーカーは基本的にこの電卓の製造・販売・サポートのみを行っている小さなメーカーで、 そこからして既存の巨大メーカーが製造している電卓とは大きく異なっています。 MicroPythonを搭載し、Pythonでプログラミングが出来るようになっています。
この機種には普通の高機能電卓と異なる点が多々ありますが、まず目につく特徴はキーアサインです。 一般に高機能電卓では、2乗・累乗・平方根・指数・対数などの普通の関数電卓ではよく使われるはずの機能が表側になく、 シフトキーを使わないと入力できない場合が多いですが、 この電卓ではこれら全ての機能が単独のキーとして割り振られています。
虚数単位 i にまで単独のキーがある関数電卓は、NumWorksの他はおそらくCASIO fx-5800p系統くらいだと思います。 しかしNumworksは多くの日本製モデルとは異なり、三角関数・指数関数・対数関数が複素数を引数に取れるようになっています。 このため、虚数単位の単独キーにちゃんと使いどころが用意されており、「こんなんにキーを1個割くくらいならもっとよく使う別の機能を割り振ればよかったのに...」というもどかしさを感じることがありません。 「出来る限り少ないキー入力で迅速に計算したい」という人にはこれ以上無い機種だと言えるでしょう。
ですがNumWorksの最大の特徴は、何と言っても「ハード・ソフトが両方ともオープンソースである」ということに尽きます。 ハードウェア・ファームウェアの両方ともの技術仕様が公式サイト上で公開されており、特に後者はOSSとしてGitHub上で開発されています。 www.numworks.com github.com この特徴は、市販されている関数電卓(グラフ電卓)としておそらく史上初のものだと思われます。 こうしたオープン性もあって、NumWorksは新興機種でありながらマニアから人気を集めています。
実際にできること
ここまでは高機能電卓がどういうものなのかイメージを掴んで頂くため、実際の機種について解説してきました。 ここからは実際の例を見て、高機能電卓のマニアがどのような遊び方をしているかを紹介します。
多様なユーザーコミュニティ
実例について紹介する前に、前提知識として(海外の)高機能電卓マニアのユーザー層やコミュニティについて説明を挟む必要があります。 まず、アメリカを始めとする一部の外国では、中等教育の数学の授業や大学入試にて高機能電卓が利用されることが一般的です1。 そうした教育を受けた中高生にとっては、高機能電卓はいわばありふれた学用品の一つです(多分)。 さらに近年ではSTEM教育のブームなどによるプログラミング教育の需要の高まりにより、 各メーカーからPythonを搭載した高機能電卓がいくつも登場するほどになっています。
このように、海外では高機能電卓を使う人間の母数が多いことから必然的にマニアの数も多く、 インターネット上には主に英語圏・フランス語圏の高機能電卓のマニアが情報交換を行うフォーラムがいくつも存在します (中国語圏については、フォーラムは分かりませんがマニア自体の存在は確認しています)。
日本人の高機能電卓のマニアがどんな人物なのかについては、私にはほとんど知見がないので説明を避けます。 ですが(高機能電卓ではない)普通の関数電卓のマニアの代表格は、やはり東海大学の遠藤雅守教授でしょう。 氏は物理学科教員としての立場から、実験系物理学の学習・研究において使いやすい関数電卓を求め、レビューや考察を『関数電卓マニアの部屋』というウェブサイトにまとめられています。 しかし氏は「関数電卓は高機能である必要はない」というポリシーを表明されており、 その視点は国内外のギーク的な高機能電卓マニアとは大きく一線を画しています。 ただ一つ間違いなく言えるのは、日本人の高機能電卓マニアは海外のそれよりも明らかに数が少ないという事です。
さて、実際にそうしたマニア達がどのような遊び方をしているのかを見ていきます。
物理演算
まずはこちらの動画をご覧ください(90度左に傾いているので注意)。 drive.google.com
これは私が3年ほど前に撮影した物です。 高機能電卓のデフォルトの機能を使って物理演算エンジンを呼び出し、電卓のUIから操作しています(元はユーザーマニュアル記載の動作デモであり、私がゼロから考えて作ったものではありません)。 ディスプレイ右側の目盛りをいじることで、跳ねるボールの数を増減しています。
有名ゲームの移植
スマッシュブラザーズを高機能電卓に移植した猛者もいます。 gigazine.net
フルカラー表示のモデルではMinecraftの移植もあります。 www.youtube.com
なお、高機能電卓へのゲーム移植は割とメジャーな分野で、Doomなどの他の有名ゲームの移植版もたくさんありますし、 新しい高機能電卓が出るたびにファミコンエミュレータが移植されていたりもします。 そもそも高機能電卓は学生が使うものでしたから、電卓でゲームをしたいという欲求を育む土壌がそもそも存在したのでしょうね。
Linux起動
Linuxの起動も割とメジャーに行われています。
下の動画では、Linuxの起動をしつつ元々の電卓のOSも起動できるようにするというデュアルブートを実現しています。 www.youtube.com
気象数値予報
また手前味噌で恐縮ですが、私は上で挙げたHP50gを使って「気象の数値シミュレーションをやる」という試みをやったことがあります。 気象学も数値計算もよく分からないままFORTRANのコードをRPLに移植しただけの代物なので挙動は全くもってガッタガタですが、 高機能電卓の可能性を示すという点ではそれなりに面白いことが出来たと思います。
詳細は下記事からPDFファイルをご覧ください。 stepney141.hatenablog.com
時間不足のため浅い内容になってしまったのが悔やまれますが、まあざっとこのような感じです。 高機能電卓は枯れた技術のようにも一見思われますが、実はそのディープな世界では今日も日進月歩で技術革新が行われ、 沢山の種類のソフトウェアが開発・配布され、さらに様々な試みがなされています。 皆さんも関数電卓プログラミングにチャレンジしてみてはいかがでしょうか?
12月中旬 1月以降をメドに、実際の関数電卓プログラミング入門手順について書いた記事を出す予定なので、記事が出たらそちらもぜひお読みいただければ幸いです。
※高機能電卓のよりディープな世界の話を書きました stepney141.hatenablog.com
【翻訳】Meet the Dagaz ! 〜汎用ボードゲームソフトウェアの開発〜
この文章について
ITエンジニア・ボードゲーム愛好家のヴァレンティン・チェルノコフ(Валентин Челноков)氏は、様々な種類のボードゲームをコンピュータ上で簡単に実装するためのフレームワークの開発に取り組んでおられ、これを "Dagaz(ダガズ) Project" と名付けています。
同様のものとして1998年に開発された "Zillions of Games" というソフトウェアが極めて有名ですが、その仕様には問題点や限界が多く見られます。 チェルノコフ氏は ZoG の問題点を解決した新たなソフトウェアを開発すべく、これまでに5年以上の歳月をかけて本体・デモを合わせて総計数十万行に及ぶコードベースを実装し、極めて汎用的で利便性の高いフレームワークを構築してきました。
しかしそれにもかかわらず、その知名度はフレームワークの完成度に見合ったものとなっていないのが現状です。 その一因としては、ボードゲームマニアのコミュニティの間でDagazの存在が十分に周知されていないことが大きいと言えるでしょう。 氏が行っている宣伝活動は氏自身の母語であるロシア語での解説記事執筆が主であり、英語圏のコミュニティにDagazのインパクトが未だ届いていないのです。
今回チェルノコフ氏がボードゲームのオンラインマガジン "Abstract Games" 誌に執筆した記事 "Meet the Dagaz!" は、氏が Dagaz に関して執筆した2番目の英文記事であり、Dagazプロジェクトの概要・歴史・コンセプトを簡潔に説明したものとなっています。 本稿はチェルノコフ氏の許諾を得て、その記事を日本語に翻訳したものです。 特に補足が必要と思われる箇所については、注釈として訳注を付けています。併せてご覧下さい。 私の英語力は大変拙いものであるため、本稿には少なからぬ数の誤訳が含まれている可能性があります。 また意訳しているため、文の構成が原文と一致していない箇所があります。 誤りがありましたら訳者まで厳しくご指摘頂ければ幸いです。
なお、DagazプロジェクトはGitHub上で公開・配布がなされています(公式サイト(動作デモ有り)、本体リポジトリ、公式サイトのリポジトリ)。 ぜひ、公式サイト上のデモに実装されているゲームを色々と試してみて下さい。
- 原著者:Valentin Chelnokov
- 日本語訳:yumiya (stepney141)
- ソース:Dagaz - THE NEW ABSTRACT GAMES
※2022-12-09:誤訳や日本語としておかしい文章を修正
訳本文

私が名付けた "Dagaz" というプロジェクト名は、全23個の古代ルーン文字のひとつ"ᛞ"に由来しています。この文字が持つ意味の解釈の一つは「復活(revival)」です。 このルーン文字の形に私はボードゲームの駒を連想しますし、さらには「ゲームを遊ぶ人・ゲームを作る人双方のための汎用的なゲームソフトウェアを作り、これを用いてアブストラクト・ゲームにより興味を持ってもらいたい」――私のそのような考えが、文字の意味ともぴったり対応しているように思われるのです。
2つの出来事がきっかけで、私はボードゲームにのめり込むようになりました。 1つ目は、ドミトリー・スキュルーク氏(彼はロシアの作家で、囲碁・チェッカー・マンカラ系ゲーム(中でもアフリカに分布する系統のもの)の偉大な愛好家です)にお会いしたこと。 2つ目は、それと同時期に "Zillions of Games"(訳注:以下、"ZoG"と表記1)という汎用ボードゲームソフトウェアに出会ったことです。 運の悪いことに、私がこのソフトを知った頃には既に、ZoGに対する界隈の関心は衰え始めていました2。 ですが私はそんな状況を尻目に、ZoG上にいくつものゲームを実装しては、 ZoGについての解説記事を大量に執筆するという活動を続けました。 ZoGでゲームを実装する際には、 "Zillions Rules File"(以下、省略して "ZRF" と表記します)という独自のスクリプト言語を使用してゲームのルールを記述するのですが、 ZRF の強力さにはまさしく心を揺さぶられるものがありました。 ルールも見かけも全く異なる別々のゲームをこんなにも沢山作れるなんて、それ以前の私にはまるで想像もつかないことだったのです。
しかし、 ZRF の扱いに習熟すればするほど私はその欠点にもだんだんと気付いていくこととなりました。 その欠点とは「ZRF で簡単に実装することが出来るのは、極めて単純な――特にチェッカーやチェスに類似している――ルールのゲームのみである」ということです。 マンカラなどをはじめとしたより複雑なゲームを ZRF で実装しようとすると、ルールの記述は巨大で漠然としたものになり、動作も低速かつ信頼性に欠けるものになってしまいます。 この問題に直面した私は解決策を求めて、"Axiom Development Kit" を活用するようになりました。 これはグレッグ・シュミット氏が開発した ZoG の拡張プラグインで、DLLファイルとして ZoG に読み込ませることで動作します。 Axiom を用いることでリスモマチア(Rithmomachia)(AG15を参照)などの比較的複雑なゲームも実装できるようにはなったのですが、これを使っても実装はやはり難解で時間を食うものになってしまうのです。 まだこの他にも欠点があります。というのは、Axiom と ZoG はいずれも Windows 上でしか動作しないのです。しかし私が求めていたのは、クロスプラットフォーム対応でどこでも動く、何ならスマートフォン上でも動作するソフトウェアでした。
以上のような欠点を解消したいという視点で考えると、開発に利用できる技術は自ずと限られてきます。 ほとんどあらゆるモダンなWebブラウザがネイティブにサポートしているプログラミング言語と言えばただひとつ、それは JavaScript です。 Javaアプレットを触るという選択肢は取りたくありませんでした。何しろ、今や時代遅れで不便な技術ですからね。 Web Assemblyもまた、別の理由から私にとっては適しませんでした。 というのも、私の目標は「あらゆるユーザーが自由にオープンソースのコードを参照でき、ソフトの仕組みを理解して、ZoG 同様にしかしずっと簡単に自分でゲームが作れるようにする」ことだったからです。
もちろん完璧なアプローチというものは存在しない訳ですから、当然JavaScriptという案にも欠点はあります。C++やJavaといったプログラミング言語と比較して、JavaScriptでシステムを書くと、ユーザーが改造しやすくなる代わりにパフォーマンスが比較的低くなってしまうのです。 幾度も失敗を重ねた後、私は、ゲームを動かしながら ZRF を直接読み込んで解釈するというのは動作速度の問題から不可能らしいということに気付きました。 結局、私は ZRF を JavaScript に変換する "Z2J" というユーティリティを作ることでこれを解決しました。 Z2J で変換されたルール記述のコードは「自動生成臭」が強く、人間が直接編集するには不向きな難しいものですが、それでも ZRF のようにルール記述として解釈可能なようになっています。
図1:ロシアン・チェッカー
私はまず、ロシアン・チェッカー(ルールはこちらを参照)から実装を始めました。 個人的に、この系統のゲームはあまりに過小評価されているという思いを常に持っていたからです。 このゲームの複雑なルールをきちんと理解できなくては、これ以上のあらゆる開発は無意味でしょう。
このゲームの注目すべきルールとして、まず「着手の複数性」があります。 これは「一回の着手において、立て続けに複数回連続して駒を動かすことが出来る」という大変重要な決まりです。 チェッカー類に関して他に重要なこととして、「着手の優先順位」というルールの実装をしたことが挙げられます。 このルールは、もしも取ることが出来る相手の駒があるならば必ず取らなくてはいけない、というものです(例え相手の駒を取ることで自分が不利になるような状況であってもです)。 このゲームのために私が最初に考えた「着手の優先性」の実装は、後に他のゲームの実装に移った際に根本から再考・修正をしなくてはならなくなったのですが、ともあれこのメカニズムがDagazプロジェクトの基礎をしっかりと形作ることになりました。
チェスにおいては、「複数の駒が一回の着手で一度に移動する場合がある」(例:キャスリング)ということに私は気付かされました。 さらに、「駒が動けるからと言って必ずしもその駒を動かしていいとは限らない」という性質もあります――例えば、キングがチェックをかけられてしまうような場所に自分からキングを動かすことは決してやってはいけないことになっています。 このため、私はチェックメイトを判定するアルゴリズムを実装する必要がありました。 チェックメイト判定(禁止手排除)はチェッカーの「着手の優先性」よりも困難です。何故なら、禁止手排除は「駒を取る手」と「駒を取らない手」の両方に適用されるからです。 また、チェッカー系ゲームでは禁止手について様々な判定基準が存在しうるため、これも単純とは程遠いと言えます。 可能な限り多く相手の駒を取らなければならないというゲームもある一方、例えばフリジア・チェッカー(AG10を参照)などのゲームではそれに加え、「成った(昇格した)」駒を先に取るという優先順位が設けられています。
これらのとても複雑な概念をZRFの判定ロジックで記述することに貴重な時間を割き、さらにそれをJavaScriptに翻訳するなんて、例えそのやり方を知っていたとしてもそんなことをしている余裕は私にはありませんでした。 とにかく、そのようにしてZ2Jで得られるコードはまるで非効率だったため、直接JavaScriptで判定を書いてやる方がよっぽど理に適っていました。 というわけで、私はDagazにおいてあくまで駒の動きの基本的なルールを書くことにのみZRFを使い、複雑な判定は拡張機能として直接JavaScriptで書くことにしました。 ZRFで記述された基本的なルールに従って大まかな合法手の一覧を生成した後、ZRFでの表現が難しい処理を拡張機能で合法手に施してから、盤・駒の画面表示を更新します。 拡張機能では、複雑な判定や着手のフィルタリングなどといった様々な追加的処理を効率的にこなすことが出来ます。

図2:アタリ碁(ポン抜き囲碁)
アタリ碁3(ルールはこちらを参照)は、私が上で述べた仕組みの実例としてぴったりのゲームです。 囲碁の基本的な着手の仕方は大変シンプルで、石を盤上の空いた場所(交点)に置くだけです。 しかし、あらゆる場所に石を置けるという訳ではありません。自分の石の呼吸点がなくなるような手を自分から打つのは「自殺手」であり、そのような着手は禁止されています。 プレイヤーは、自分が石を置くと自分の石の呼吸点(石の上下左右方向に隣接する空白の点)が無くなってしまうような場所には、自分で石を置いてはいけません。また、石の一団が活きているためには、最低一つの呼吸点を持っていなければなりません4。 ゲームは次のように進行します――以上の原則を踏まえ、プレイヤーが着手した際、自分が置いた石によって対戦相手の石の呼吸点が全て潰されているかどうかを判定します。もしも相手の呼吸点がなくなっていたならば、相手プレイヤーの石を取り、盤上から取り除きます(アタリ碁では、一度でも相手の石を取った時点で自分の勝利となります)。 これらの判定と確認はZRFで記述するにはあまりに困難かつ厖大であり、ここで拡張機能の出番となるわけです。
Zillions of Gamesの動作を色々と試していた頃、私はZoGでの囲碁系ゲームの実装に関して他にも問題を見つけました。 大量の石を一度に取ると(このような状況が起こることは稀ですが、起こり得ない訳ではありません)、バッファオーバーフローが発生してソフトがクラッシュするのです。 ZoGは、各着手とそれによって発生する盤上のあらゆる変更を(ZSG棋譜という形式の)テキストとして保存します。 履歴には「この場所に石を置いた」という着手それ自体の情報のみならず、置かれた石とそれに隣接する石についてのあらゆる属性情報――どちらのプレイヤーの石か、石の位置はどこか、石は取られたか否か、など――も保存されるのです。 しかし囲碁においては、現在の盤面にたった一個でも石を置くだけで次に取られる石が完全に決定されるので、石がどこに置かれたのかさえ分かっていればそれで事足りるわけです。 囲碁やチェッカーなどのゲームでは、石を捕獲する際に石を盤上から除去する操作が伴う場合があります。Dagazではこのような捕獲を、着手の情報からゲームのルールに従って直ちに情報が求まる「副次的現象」としてみなしています。 プログラムのコア部分は、与えられたゲームのルールに則り、全ての変更と副次的現象をいつでも復元して自動で単一の変更の形に調整することが出来るようになっています。したがって、あらゆる情報を棋譜のテキスト内に詰め込む必要はありません。 結果、保存される着手の履歴は簡潔でスッキリとしたものになっています。
まだ他に1つ、Dagazが解決策を提示している既存の問題があります。それは、盤上の駒の位置をどうやって決定して画面に描画するかです。 ZoGでは「駒の属性を"Yes = 1"や"No = 0"のような感じで記述したビットフラグを複数持っておき、それらを各々の駒に割り当てる」という方法を取っていました。 これをチェスのキャスリング(ゲーム開始から今まで動いたことがないキング・ルークを一手で入れ替える操作)を例に解説しましょう。 ZoGのプログラムは駒に関するビットフラグを内部的に持っており、その中には「これらの駒は、キャスリング可能な条件から外れるような動きをしたか」というフラグも含まれています。キングやルークの駒が動くと、このキャスリング判定用のフラグがNoからYesに切り替わり、プログラムはこれを参照して「キャスリングは出来ない」と判断するというわけです。 Dagazは、ZRFが抱えていたデータ型に関する制限を回避しています。 真偽値以外にも、他のあらゆる種類の属性とそれに適する型の値を内部に持っておくことが出来るのです。 例として、穴(house)の中に入れる石(seeds)の数を表示するために整数型の値を使用しなければならない、マンカラ系ゲームの実装を見てみましょう。
図3:オワレ
オワレ(ルールはこちらを参照)はアフリカのマンカラ系ゲームの中でも最も有名なものです。 ゲームは穴(house)1つにつき各4個ずつ石(seeds)を入れた状態でスタートします。 各手番では、まずプレイヤーは自分の陣地である6つの穴(両サイドの一回り大きな穴は「スコアリング・ハウス」といいます)の中から1つを選びます。 次に、その穴の中にある石を全て取り出し、その1つ右隣の穴を起点にして半時計回りの順番で、取り出した石を各穴に1個ずつ落としていきます――このプロセスを「石撒き(sowing)」と言います。 ただし、スコアリング・ハウスには石を撒きません。またスコアリング・ハウスが石撒きの起点になることもありません。 「最後に石を撒いた穴が対戦相手の陣地にある」なおかつ「石を撒いた結果その穴に2個または3個の石が入っている」場合、自プレイヤーはその穴の中の石を全て捕獲します。捕獲した石は穴から取り除き、自分のスコアリング・ハウスの中に移します。 加えて、最後から1つ前の穴も上の条件を満たしていた場合は同じように石を捕獲し、さらにその1つ前も条件を満たしていればまた同様に...という具合で、条件を満たさない穴にぶつかるまで時計回りに遡って捕獲を続けます。 以上のルールに従い、より多くの石を捕獲して自分のスコアリング・ハウスに移すことを目指すのがこのゲームの目的です。
Zillions of Gamesでマンカラ系ゲームのロジックを実装するのは、様々な理由から困難です。 まず最初のハードルは、このゲームで使う石の画像がたった1種類・1枚だけであるということです。 ZoGでは、「一つの穴に同じ種類の石や駒が複数個存在している」という状態を描画することができません。しかも描画処理をユーザーがプログラミング言語で拡張することも出来ないため、ZoGにおいてこの問題を直接どうにかすることは不可能です。 このためZoGでは、異なる数の石が穴に入っているという情報は、それぞれ別の種類の駒が存在する状態として記述してやる必要があります。言い換えると、石が1個あるという情報は内部的には駒1個が存在する状態として、石が2個以上という情報は内部的にはまた別の種類の駒が1個存在する状態として、それぞれ符号化します。 この方法では、対応する個数の石の組を記述するために必要な画像の数が増える問題が生まれます。 ZRFには整数値や整数の演算に関する機能もないので、この方法においても通常の加算と減算をエミュレートするためにビットフラグを利用しなくてはならず、実装は依然として複雑になります。 Axiom Development Kitでは整数演算が追加されていますが、それを使ってもなおマンカラ系ゲームの実装は難しいままです。 Dagazでは、このようなゲームの構造をもっとずっと単純に記述出来るようにしました。 しかも、この方が動作がより効率的になる傾向まであるのです。
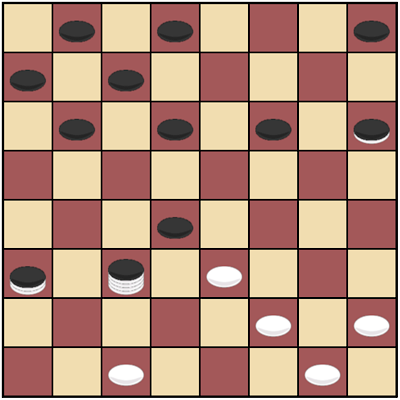
図4:カラム・チェッカー
ロシアン・カラム・チェッカー(詳しくはAG1などの号を参照)――バシュネ(Bashne)という名前でも知られています――もマンカラ系のゲームとよく類似していますが、ひとつだけ相違点があります。 それは、このチェッカーではマンカラのように石を一つの穴の中にただまとめておく訳ではなく、石を一つにまとめる順番も重要な要素になっているということです5。 特定の順序で配置された要素を持つ"列(column)"を表現するのは整数値だけでは不十分なため、私はDagazが内部で保存している属性により多くの種類のデータ型を追加しました。 一つの列の中に石がどのような順番で積み重なっているのかを記述するため、Dagazでは属性情報として文字列を利用しています。 実際の所、Dagazでは配列でも他のどのようなデータ構造でも利用可能なようにはなっているのすが、外部ファイルへの保存のしやすさを考えて、文字列を使うのがベターかと個人的には思っています。 ソフトウェアレンダリングを用いて駒や石を表示するというのは、駒や石をプログラムで制御する上で非常に強力な機能でもあります。 このオプションをどう利用するかの例を解説しましょう。 囲碁には「スーパーコウ(超コウ)」というルールがあります6。これは、以前の盤面の状態が再び出現するような手を打ってはならないというものです。 このルールに従った禁止手を可視化するために、「禁止手になるからこの交点には石を置けない」という意味として盤上の交点の上に四角形を描画します。この正方形は駒や石として扱われる訳ではなく、単に画像として盤上に表示されます。 連珠(AG5とAG6を参照)では局面に応じて禁止手も変化しますが、禁止手の可視化には囲碁と同じく、ソフトウェア側で描画される四角形の仕組みを採用しています。

図5:連珠
局面を前の状態に戻すことを禁止するゲームは、かなり複雑になりえます。 モラバラバ(Morabaraba)(ルールはこちらを参照)というゲームは、盤上の空いている場所に自分の駒(このゲームでは"牛"と呼びます)を並べ、自分の"牛"を3匹並べた列(このゲームでは"ミル(mill)"と呼びます)を作ることを目指すものです。 プレイヤーはミルを1つ作ったら敵の牛を1匹「撃ち」、その牛を盤上から取り除きます。撃たれた牛はその時点で二度と盤上に置くことが出来なくなります。 ミルを構成している牛は、相手の牛が全てミルになっていない限り撃たれることはありません。 別の新しいミルを作るために分解されたミルは、次の手番で再びミルになることは出来ません。 図6には赤いバツ印が描かれていますが、これは直前の局面で壊されたミルの位置を表すものです。 しかし、バツ印が付けられた場所であっても、この手番でミルを再び作り直さないならば、次の手番以降でそこに牛を置くことが出来ます。
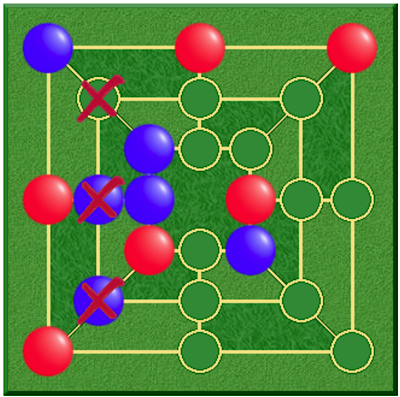
図6:モラバラバ
この「盤上に駒や石とは関係ない画像を表示する」という機能は、反復同形を禁止する以外の用途にも利用することが出来ます。 ゲームの中には、ゲームに関する何らかの情報がプレイヤーに隠されたまま進行する種類のものがあります。 普通、そのような種類のゲームと言えばカードゲームなどが代表的ですが、チェス系のボードゲームでも同じ類のものがあります。 暗闇チェス(Dark chess)というゲームでは、プレイヤーは自分の駒が利いているマス以外のマス目の情報を把握することが出来ません。 同じアイデアを他のチェス系ゲームに持ち込むことも可能です。
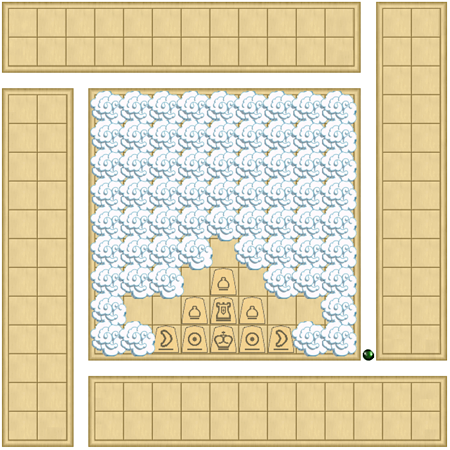
図7:暗闇四人将棋
暗闇四人将棋は四人将棋の変種です。 四人将棋は、日本の有名な7四人向けゲームです。 小型・中型の盤で遊ばれる他の伝統的な将棋類と同じく8、四人将棋は「持ち駒」のルールがあります。これは、「獲得した相手の駒を自分が保有し、自分の駒として使用することが出来る」というものです。 盤上にある駒を動かす代わりに、プレイヤーは自分の持ち駒を盤上に新しく置くことが出来るのです。 四人将棋の場合プレイヤーは4人いるので、4枚ある王将が1枚取られてもゲームは依然として進行し続けます。 獲得した駒は王将も含めて全て自分の持ち駒となり、王将を持たないプレイヤーはそれ以上ゲームを続けることは出来ません9。 そして、四人将棋は「暗闇で指す」バリエーションもあります。つまり暗闇チェスと同じように、「戦場の霧」という概念――ここではすなわち「自分の駒が利いていないマスの情報を隠す」ということ――を導入したのが、暗闇四人将棋という訳です。
これらの「暗闇のゲーム」が持つ構造的な特殊性を発展させて、Dagazでは空のマス目・駒があるマス目の両方を隠すための2つの特別な機能が利用できるようになっています。駒を「半透明」の状態にできる上、必要に応じて、マス目が空かどうかに関わらず、新しいレイヤーを追加するようにしてマス目の上にさらに画像を被せることができます。 個々の駒の表示は、他の駒の利きに入っているか否かによって制御されます。 もしも敵の駒が自分の駒の利きに入っていないならばその駒は表示されませんし、自分の駒についても同じようなチェックが行われ、敵の駒の利きに入っていない自分の駒は半透明になって表示されます。 原則的には、このようなチェックをするだけで隠す必要のある駒は全て隠すことが出来るはずです。 しかし、マス目が空なのかそれとも半透明の敵駒があるのかまでも明らかになるわけではありません。 このため、私はあるユーザーから「自分の駒が利いていない空のマス目にも目印を付けて欲しい」という要望を受けることになりました。 その解決策として、盤上に「雲(clouds)」を描画するようにしました(図7参照)。 「雲」は、そのマス目が自分の攻撃の範囲外にあることを示すためにソフトウェア側で描画された画像です。 プレイヤーは、現在の手番で「雲」がかかったマス目の中に半透明の敵駒が存在する可能性があり、そのマス目が空であるかどうかは分からないことに留意します。 ですが、「雲」も駒も存在しないマス目が正真正銘の空っぽであることは明らかです。
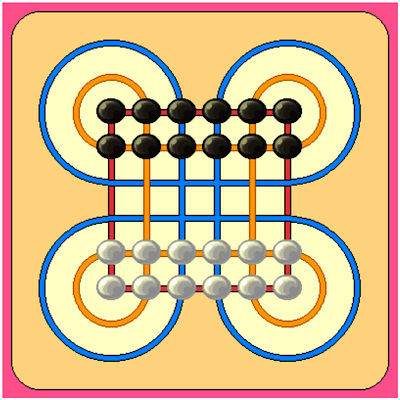
図8:スラカルタ
このような抜本的な変更は、ゲームの表現をより良くすることのみに貢献している訳ではありません。 ガラ(Gala)("農民のチェス(Farmer's Chess)"としても知られています)のようなゲームでは、駒が移動中に行き先を変えることがあります。 スラカルタ(Surakarta)(AG13を参照)というインドネシアのゲームでは、より興味深い状況が見られます。 このゲームにおける「相手の石の捕獲」の概念は、盤に描かれている合計8つのコーナーループのうち少なくとも1つに沿って自分の駒を動かし、相手の駒の上に着地してそれを取るという動作からなっています。 「捕獲」「非捕獲」のどちらの移動も、空のマス目を対象とした任意の方向への単一ステップとして実行されます。 このため、Zillions of Gamesのように「捕獲」の着手を開始位置から終了位置までの直線的な移動として表示すると、「捕獲」の移動が「非捕獲」の移動と混同されてしまう可能性があり、プレイヤーを混乱させるだけになってしまいます。 Dagazにおいては、駒の動きのアニメーション表示が可能なようにしました。 駒や石を動かすと、直線移動・斜め移動・曲線移動のいずれであろうと、駒や石が複数の地点を順番に通過するような動きをしても、その軌道全体がアニメーションとして表示されます。 スラカルタなどの一部のゲームでは、この機能は特に重要です。 また実用的な意味以外でも、この表示は視覚的に優れたグラフィックエフェクトとして機能します。

図9:ウル王朝のゲーム
最後に、ウル王朝のゲーム(Royal Game of Ur)について触れておきましょう10。 このゲームは長い年月の中でルールが完全に失われてしまい、発掘された当初は誰もその遊び方を知りませんでした。 歴史的見地から再現を試みたルールがいくつか提案されていますが、中でも私はこのルールが特に好きなのです。これは私の友人であり、作家でボードゲーム普及家のドミトリー・スキュルーク氏が考案したものでもあります。 当然ですが、Dagazプロジェクトではこのゲームを見逃さずに実装しているんですよ!
総括すると、私はボードゲームをより手早く実装するための便利なツールを皆さんにご提案したいと思っています。 DagazはZillions of Gamesプロジェクトのベースとなるアイデアを受け継いでいます。しかしZoGとは異なり、DagazはMITライセンスで公開されている完全オープンソースで無料のソフトウェアです。 現時点では、どのようなボードゲームでも遊べる汎用AIを搭載してはいませんが、思考エンジンをいくつか組み込んであり、必要に応じてそれらを全く別々のルール向けに改造することが可能です。 私は数年間もこのプロジェクトに取り組んでいまして、この短い記事でその全貌をお伝えするのは難しく、説明を端折った部分もあります。 もしも私のプロジェクトにご興味がお有りでしたら、お気軽にメールでご連絡下さい。 私のメールアドレスはDagazプロジェクトのGitHub Pagesをご覧下さい。
- これ以降の原文では、Zillions of Gamesは単に"Zillions"と略称されていますが、訳文では分かりやすさのため"ZoG"に統一しました。 略していない箇所はそのままにしてあります。また、原文では"ZRF"というドメイン固有言語の構文の制限を"ZoG"というソフトウェア自体の機能の限界として説明している箇所が多いことにも注意して下さい。↩
- 原文"Unfortunately, I got acquainted with this project quite late, when the main excitement around it had already begun to wane." ここでは"the main excitement"を「ZoGで色々なゲームを作ること」と解釈した上で意訳を試みました。↩
- Wikipediaの言語間リンクを見る限り、アタリ碁(Atari Go)は日本では「ポン抜き囲碁」と呼ばれているそうです。日本においては主に初心者の教育用であり、石を取る感覚を掴んだら卒業するものとされているようですが、個人的には9路盤でやると中々楽しいように思います(訳者が囲碁初心者だからかもしれませんが)。↩
- 訳者は囲碁のルールをほとんど知らないため、日本棋院と Wikipedia のルール解説を基にかなり強引に訳しています。誤りがありましたらご指摘頂ければ幸いです。↩
- ロシアン・カラム・チェッカーでは、取った石を自分の石の下へ順番に積み重ねていき、石の "列(column)" を作っていきます。実際にDagazのデモ実装で遊んでみるとどういうことかよく分かると思います。↩
- 『一般的なコウのルールと違い、1つ前の自分の着手時の盤面とだけではなく、対局開始からのすべての盤面との同形反復を禁止したルールのこと。三コウの問題が発生しない。』(参考:囲碁用語辞典) 中国や欧米で使われるルールのようです。↩
- 原文では"a famous Japanese games for four players." 言うほど有名か?変則将棋マニアしか知らんだろ、という気もしますが、日本語版ウィキペディアによればこち亀で紹介されたこともあったらしいので全く無名ということもなさそうですね。↩
- 原文:"As with the other classical Shogi games which are played on small and middle size boards, Yonin Shogi saved the 'drop rule,'..." 古将棋の場合、持ち駒を使えるものはむしろ少数派に近いというのは明らかですが、原著者は将棋のマニアではないので仕方ないと思います。↩
- 原文"All captured Kings as well as other pieces are sent to the hand reserve, and the player left without a King cannot move his pieces." ただし日本版Wikipediaでは「詰められた王将はその場から動けず障害物とする」というような事が書いてあります。原著者がルールを誤解している可能性があります。↩
- このゲームの詳細については、英語版 Wikipedia の該当記事を参照することをオススメします。↩
備忘録: Manjaroのパッケージアップデート周りについて(WIP)
忘れるたびにブックマークを参照するのがいい加減面倒になってきたので備忘録。wiki.manjaro.orgや個人ブログの記述を自分用にまとめる。まだまとめ途中。
pacmanのミラー先
pacmanが参照するミラー先のリストは/etc/pacman.d/mirrorlistに格納されている。
ミラー先のリストを速度順に並べ替えた上で、ローカルの情報を新しく設定したミラー先と同期するには次のようにする。
sudo pacman-mirrors --fasttrack && sudo pacman -Syy
しかし、上の操作でミラー先を設定しても、時々えげつなくミラー先への接続が遅くなる時がある。
これはpamac-mirrorlist.serviceというデーモンが、定期的&自動的にミラー先のリストを/usr/bin/pacman-mirrors -f8 (ミラー先を速度順で上位8つ飲みに設定) で書き換えてしまうからである。
いくら書き換えられようが近くのサーバが指定されるなら別に良いのだが、実際はそうではなく、このデーモンによって更新された後は決まってめっちゃ遠くのミラー先が指定されると来ているから始末が悪い。理由はわからないし調査する元気もない。
自分が今これを書いている時点でのリストは、接続優先順にドイツ・ドイツ・ハンガリー・UK・ドイツの5つが指定されている。ドイツ好きすぎだろ。欧州に集中しているのには何か理由がありそうだ。
ともかく、参考文献を元にデーモンのドロップインファイルを作成してデーモンの処理の変更を試みたが、作成したドロップインの情報が全然反映されていない。なぜだ。
pacmanのオプション
まだ調査中
参考文献
2020/09に読んだ本のまとめ
おはようございます。
テレビ業界では何時であろうと関係なく「おはようございます」を使うそうですね。ホントかどうかは知りませんが。
他人に読まれてもいい個人的備忘録として、毎月初めて読んだ本の感想を簡単にまとめてみることにします(再読本は含めません)。
このモチベーションがあと何日続くか見ものですね。
読書メーターじゃなくてブログに書く理由は特にありません。情報は一元化しておいた方が良いだろうからとりまブログにすっか程度の事しか考えていません。ブログに書評を上げるという行為自体になんとなく憧れがあったということもありますが。
9月に初めて読んだ本は4冊です。少ないですね。 毎日のように新しく2冊とか3冊とか図書館で借りまくってたかつての頃と比べると衰えを感じます。 現時点で積読本が50冊強・読みたい本が300冊余りありますから、せめて1週間に2冊くらいのペースに戻していきたいところではあります。
江戸奇談怪談集(ちくま学芸文庫)
江戸時代の随筆・仮名草子・浮世草子・読本から種々の怪談奇談・都市伝説・街談巷説・道聴塗説を抜き出し、ある程度の現代語訳を加えつつも文語調にまとめた物語集。 自分は元から『捜神記』のような志怪小説から『宇治拾遺物語』のような説話集まで、こういう類の怪談奇談が好きな質なもので、非常に面白く読みました。 こういうタイプの物語集が好きな方は、同じちくま学芸文庫から『奇談雑史』という江戸時代後期の説話集(作者は平田篤胤の弟子)が出ているので読んでみると良いと思います。
本当はこれが初読という訳ではなく、中高生時代に図書副委員長の権限を行使して学校の図書室に入荷してもらい、図書室で何回か読んでいます。 でも半分も内容を覚えてなかったから実質これが初読みたいなものです。
結構多種多様なジャンルの怪談奇談が収録されており、70ページ余りを割いて『稲生物怪録』(平田本)を全篇載せていたりもします。井原西鶴を始めとして男色にまつわる話が多かったのも印象的でした。
怪談奇談としての内容とは関係ないんですが、この中のとある一篇で「十六むさし」なる包囲系のボードゲームが登場します。
検索したところ、これはどうも明治期までは良く知られていたボードゲームだった模様です。
自分は夏あたりから目下のところ汎用ボードゲームエンジンに興味を持っており、たまたま選んだ本にこのようなあまり知られていないボードゲームへの言及があったことに何だか奇妙な感覚に襲われました。ある意味、これがこの夏自分にとって一番奇妙だったことのように思われます。
椿井文書―日本最大級の偽文書(中公新書)
中世の古文書を装いながら、実は一人の人物によって江戸時代後期に作成されていたとみられる偽書群「椿井文書」について紹介している一冊。偽書の内容紹介に留まらず、偽書であるはずの椿井文書が様々な要因から各時代のアカデミアの史料批判の目をすり抜けてしまい、現代でも郷土史研究、さらには地域の歴史教育の中にまで活用されてしまっているという実態を報告しています。一般向けに書かれていますが筆致は割と専門書寄りっぽい?歴史の専門書を読んだことないから分からん。
出版当時からTwitterの歴史・民俗学クラスタでかなり話題になっていた様子を観測していたので、かねてから読んでみたかった本でした。個人的には下の『偽書が揺るがせた日本史』と併読することをお勧めしたいです(『偽書が揺るがせた日本史』はガイドブック的な感じの本なのでこれでざっと雰囲気を感じて、その後により学術書として濃密な内容の『椿井文書―日本最大級の偽文書』を読むという風にすると色々理解しやすいと思います)。
偽書が揺るがせた日本史(山川出版)
古代から現代まで日本史に関する種々の偽書を取り上げ、それらの偽書が本物であると主張する立場に反駁しつつ、偽書の内容やそれが及ぼした影響について紹介している一冊。一般向けの啓蒙書です。
先述の「椿井文書」に関しても簡単に触れられています。著者は『東日流外三郡誌』真書派の代表格だった故・古田武彦氏の弟子筋にあたる方ですが、偽書の記述を信じ込んでしまった古田氏と接した経験が、逆に著者の偽書に対する批判精神を培ったとのことで、この経緯そのものもかなり興味深いところです。
単に偽書を紹介するだけではなく、最後に5チャプターを割いて「偽書を偽書として断じつつ、いかにして偽書を歴史研究に活用していくべきか」という観点について論じているのが特徴的です。それ自体は『椿井文書―日本最大級の偽文書』でも少し触れられている事項なのですが、本書では現代の歴史研究史にも触れながらその辺をより深く掘り下げ、偽書研究の重要性についても論じています。
東京の下層社会(ちくま学芸文庫)
明治から戦前期にかけて、帝都東京にいた最貧困階級の人々の暮らしや労働・彼らが住んでいたスラム街の実態。そしてそのような人々を生み出してしまった当時の政策の問題点や知識人階層の偏見・無理解。それら「貧困住民にまつわる戦前日本社会の暗部」とでも言うべきものの実際を、当時のルポや史料を基に網羅的にまとめた一冊。スラム住人だけでなく、戦前の私娼や女工の生活苦や虐待にも触れられています。
個人的に印象に残ったのは「(永井荷風の)花柳小説は私娼の実態を無視している」という指摘です。本書によれば、荷風の描く花柳界の女性像は「荷風の生活感や美意識をそのまま女性のキャラクターに反映させたものにすぎず、現実の女性たちの苦悩は捨象されている」とし、また私娼を取り巻く労働環境の描写についても「どの程度の根拠を有するものなのであろうか」と、小説と実態との乖離をかなり直接的に批判しています。本書はあくまで貧困階層の本である以上、著者がここにフェミニズム的視点を意図していたかどうかは定かではありません(ちなみに著者は男性です)。しかしフェミニズムといえば俗に言う「ツイフェミ」の眉を顰めるような言動しか見聞きしたことのなかった自分にとって、同時代の史料や体験記というリアリズムに裏打ちされた本書の指摘は、かなりの説得力とインパクトがある論説として感じられました。
まとめ
もっと本を読みましょう(@自分)。
TypeScriptの環境構築わかんないよ〜!
数日前、特にフロントエンドがやりたいわけではないのですが突然Typescriptに入門したくなり、LGTMが数百個ほど付いているQiitaのTS導入記事をいくつか選りすぐって*1参照しながらTSの環境構築に挑みました。
しかしどの記事でもTSの実行環境以外のツールやフォーマッターやら何やらを大量に突っ込んでいて、フロントエンド開発やモダンなJavascriptに一切触れたことがなかった自分には、一体何がどうなっているのか全く理解出来ませんでした。
記事を読む15分前にNode.jsを入れたばかりの人間にとっては、WebpackやらBabelやらtsconfigやらをいきなり導入・設定させられるのは少々荷が重すぎたようです。
そういうわけで、目下のところ色々な記事を読み漁り、Typescriptの周辺ツール・定番ツールの役割の把握に努めています。
個人的な備忘録も兼ねて、自分が読んだ記事をジャンル毎にまとめておきます(随時更新)。
概論
Typescript本体
npm
Webpack
*1:記事内容の正確性や充実度や需要はLGTMの数によってある程度測れるだろう、と考えたため
GitHub API v3で「自分がstarを付けたリポジトリの一覧」を取得する
表題のとおりです。
自分がstarを押したGitHubリポジトリのURLをChromeのブックマークに追加したくなったので、GitHub側で用意されているREST APIを使って情報を取得することにしました。
個人的な備忘録も兼ねて、順を追って方法を解説します。
1. 任意のユーザーの情報を取得するREST APIを使い、自分が押したstarの情報を取得する
1-1. star情報取得APIの叩き方
curl
curl -H "Accept: application/vnd.github.v3+json" https://api.github.com/users/stepney141/starred
wget
wget --no-check-certificate --header="Accept: application/vnd.github.v3+json" -q -O - https://api.github.com/users/stepney141/starred
このように、 GET api.github.com/users/ユーザー名/starred が該当するエンドポイントとなります。上の例では私のアカウントを指定しています。
情報は普通にjsonで返ってきます。エンドポイント自体の詳しい仕様は、下記参考文献 1.を参照してください。
1-2. とりあえずこうやればOK
curlの使い方をよく知らないので、個人的に使い慣れているwgetを使って叩いてみます。APIというと何かとcurlが使われがちですが、wgetでも普通に行けます。
#!/bin/bash
wget --no-check-certificate \
--header="Accept: application/vnd.github.v3+json" \
-q -O - \
https://api.github.com/users/stepney141/starred\?per_page=100\&page={1..3} \
| jq add -s \
| jq '.[] | [ .full_name, .html_url, .description ] | @csv' -r \
> stars_repo.txt
処理の流れとしては
「Bashのブレース展開を使用し、wgetでjsonを一気に3つ入手
-> jqに渡して結合
-> さらにjqに渡して『リポジトリ名』『ブラウザ用URL』『リポジトリ説明文』のみを抽出、CSV化
-> txtに出力」
という感じです。
wgetのオプションについて:
--no-check-certificate:接続先のSSL証明書のチェックを切る。wgetのSSL関連エラーはこれをつければとりあえず全て解決する
-q:wgetからのシステム出力(エラー表示やダウンロード情報など)を全てミュートする
-O -:ダウンロードした内容を標準出力に流す
補足事項
2. 現在認証中のユーザーの情報を取得するREST APIを使い、同じことをする
さて、上の手順ではprivate repositoriesの情報が取得できません。なので、認証してprivate repositoriesの情報も取れるようにします。
というのも、GitHubのユーザーページの表示では「この人は225個のstarを押してますよ」と出ていたにも関わらず、上のAPIで私が取れたのは224個だけだったのです。
このため「もしかしてprivate repositoryが抜けてるのかな?」と考え、認証して試してみることにしました。
GitHubの認証方法にはいくつかあるようですが、今回はネットですぐ情報が集まり、なおかつTwitter APIで触ったことのあるOAuth Appを使うことにしました。
2-1. OAuth Appの認証のやり方
※出典:下記参考文献3.と4.
その1.
https://github.com/settings/applications/new からGitHubアカウントに紐付けられたOAuth Appを作成し、Client IDとClient Secretを入手する。
※Client ID 、Client Secretはそれぞれ環境変数 CLIENT_ID 、CLIENT_SECRET として保存しておくことを推奨します。
※Callback URLの設定は必須です。ぶっちゃけ何のURLを入れようと問題ないっぽいが、一応自分が保有/管理しているURLを使う方がいいかも? 自分は自身のgithub.ioのURLを入力しました。
その2.
https://github.com/login/oauth/authorize?client_id=$CLIENT_ID&scope=repo にブラウザでアクセスする。
そうするとApp Authorizationの画面が出てくるので、ボタンを押して承認する。
その3.
ボタンを押して承認すると、 https://stepney141.github.io/?code=0123456789abcdefg みたいな感じで、自分が指定したCallback URLにリダイレクトされる。
末尾にqueryとしてぶら下がっているCodeをコピペしておく。
※Codeは環境変数 CODE として保存しておくことを推奨します。
その4.
Code、Client ID、Client Secretを https://github.com/login/oauth/access_token にPOSTする(以下はcurlでの例)。
※この例ではCode、Client ID、Client Secretの情報がBashの環境変数として保存されていることを想定しています。適当に読み替えられたし。
curl -X POST \
-d "code=$CODE" \
-d "client_id=$CLIENT_ID" \
-d "client_secret=$CLIENT_SECRET" \
https://github.com/login/oauth/access_token
その5.
POSTすると access_token=0123456789abcdef0123456789abcdef01234567&token_type=bearer というような形式でアクセストークンが返ってくる。
これをリクエストヘッダに入れてAPIを叩く。
※アクセストークンは例によって環境変数 ACCESS_TOKEN として保存しておくことを推奨
2-2. とりあえずこうやればOK
GET api.github.com/user/starred が今回の目的に合致するエンドポイントです。詳細は下記参考文献2. を参照してください。
下に私が使った入力を示します。例によってwgetと環境変数を使っているので、適当に読み替えて下さい。
#!/bin/bash
wget --no-check-certificate \
--header="Accept: application/vnd.github.v3+json" \
--header="Authorization: bearer $ACCESS_TOKEN"\
-q -O - \
https://api.github.com/user/starred\?per_page=100\&page={1..3} \
| jq add -s \
| jq '.[] | [ .full_name, .html_url, .description ] | @csv' -r \
> stars_repo_auth.txt
これはエンドポイントが変わっただけで、処理の内容自体は上の例と全く変わっていません。
エンドポイントの詳しい仕様は下記参考文献 2.を参照してください。
で、結局このエンドポイントを使っても取れたリポジトリは224個のまま変わりませんでした。つまり、妖怪いちたりないの正体はプライベートリポジトリではありませんでした。
原因は何なのか、結局この取れなかった1個の正体は何だったのかは不明です。
個人的にはGitHub側のバグを疑ってます(実は224個が正しい数字で、GitHubの表示自体が間違っている説)。
とりあえずこの224個を手作業でChromeブックマークに追加するのは御免蒙りたいところですので、Chromeの拡張機能を作ってどうにかしようと考えています。作業完了したらまた備忘録を書きます。
その後
starしたGitHubリポジトリの情報や上で書いたワンライナーは、全部まとめてGitHubリポジトリとして管理することにしました。(Git運用法としてはEvil感がありますが)とりあえずシェルスクリプトスクリプトを実行してパスワードを入力する度にリポジトリの最新情報がpushされるようにしています。
参考文献
- https://docs.github.com/en/rest/reference/activity#list-repositories-starred-by-a-user
- https://docs.github.com/en/rest/reference/activity#list-repositories-starred-by-the-authenticated-user
- https://qiita.com/ngs/items/34e51186a485c705ffdb
- https://qiita.com/developer-kikikaikai/items/5f4f0e2ea274326d7157
VSCodeで数式入りMarkdownを書いてPDF出力をした時に試したこと
表題の通りです。Wordの数式入力の面倒さに嫌気が差したので、VSCodeでTeX入りMarkdownを書きPDF出力して優勝することにしました。
他に同じことが出来る方法をご存じの方はコメントなどでぜひ情報をお願いします。
概要
・VSCodeはデフォルトで数式のMarkdownプレビューが出来ない
・拡張機能「Markdown Preview Enhanced」(以下MPE)、または「Markdown+Math」(以下M+M)を入れ、数式のプレビューが出来るようにする
・PDF出力にはいくつかの方法がある。以下に自分が試した3つを列挙してみたが、他にも色々方法があるらしい
1. MPEのPDF出力機能を使い、.mdファイルをPDFに変換する
メリット:MPEだけで完結するので楽。安定している。PDFへの変換方法を複数の中から選べる
デメリット:デフォルトで使用できるPDFへの変換方法が1個だけ(他のは外部ツールが必要)。書式を整えるのが面倒
2. MPEまたはM+MのHTML出力機能を使い、.mdファイルをHTMLに変換し、ChromeでHTMLをPDFに変換する
メリット:HTMLを経由するのでCSSでファイルをいじることができ、書式の自由度が高い
デメリット:書式を整えるのが面倒
3. 拡張機能「Markdown PDF」を入れ、.mdファイルをPDFに変換する
・この方法の場合、数式をKaTeXのCDNでレンダリングするために「Markdown PDF」の出力テンプレートHTMLファイルを書き換える必要がある。詳しくは下記記事を参照。 qiita.com
メリット:「Markdown PDF」のオプションが豊富で書式を整えやすい
デメリット:数式が正しくレンダリングできない場合がある(できたという人とできなかったという人がいる。自分は後者。KaTeX側の問題か、あるいは「Markdown PDF」側のオンラインCSSがうまく適用されない既知の問題のせいなのか...?)
拡張機能
上で挙げた拡張機能の一覧です。Markdownの数式プレビューやMarkdown→PDFの変換を出来るようにする拡張機能は、外部ツールを使うものも含めて他にも色々あります。
Markdown Preview Enhanced
shd101wyy.github.io できること:LaTeXなど複数の形式に対応したMarkdown数式入力・プレビュー、複数形式での図表・グラフの入力、HTML・PDFなど複数形式でのファイル出力
Markdown+Math
marketplace.visualstudio.com
できること:KaTeX準拠のMarkdown数式入力・プレビュー、HTML出力(CSSファイル指定可)
MPEよりも機能の幅は狭いですが、こちらはMarkdownでLaTeXをスムーズに入出力することに特化しているようです。
なお、VSCode v1.46.0ではHTML出力が出来ないバグがあるようです(2020/06/14現在)。自分はVSCode v1.44.2にロールバックしました。
Markdown PDF
marketplace.visualstudio.com 日本語のreadmeがあるのが地味にうれしい。PDFへの変換にChromiumを使うため自動でChromiumがダウンロードされますが、インストール済みのChrome/Chromiumを使うこともできます。