超・宣言的プログラミングから始めるJavaScript Proxy入門
この記事は、「LipersInSlums Advent Calendar 2023」第15日目の記事です。
昨日の記事は、stepney141さんの「読書メーターとGitHub Actionsで、大学図書館の本を『積読』しよう」でした。
知らない人のために触れておくと、LipersInSlums とは謎の Discord サーバです。 旧 Twitter ヘビーユーザーの計算機オタクがなぜかいっぱい集まっているという特徴があります。住民からは「スラム」と通称されています。
具体的にどんなところがスラム街っぽいのかについては、melovilijuさんの5日目の記事を読めば何となくわかると思います。 lipersinslums.github.io
超・宣言的プログラミングとは?
突然ですが、皆さんは宣言的プログラミングをしていますか? 私はしてます。
フロントエンド界隈の関数型プログラミングブームの影響からか、現在では誰もが「純粋関数」「宣言的プログラミング」という言葉を唱えながらコードを書くようになりました[要出典]。
しかし「宣言的プログラミング」とは、具体的に何をもってして「宣言的」と言われているのでしょうか?
宣言的プログラミングの厳密な定義には諸説ありますが、カジュアルには「『具体的にどのような手続きを踏んで計算するか』ではなく『やりたい計算とはどんなものであればいいか』を書き連ねること」などと解されるのが一般的です。
JavaScriptにおける宣言的プログラミングの例として、以下の persons の中から「15歳未満の東京都民」を検索せねばならない状況を考えてみましょう。
ただし、
- 人の手で書かれた温もりのあるデータなので、元のオブジェクトを破壊しないでほしい
- プロパティを
genderに書き換えた上でデータを出力してほしい
という要件が課されているものとします。
const persons = [ { name: "Fuyuko", age: 19, sex: "F", address: { city: "Ibaraki"} }, { name: "Asahi", age: 14, sex: "F", address: { city: "Tokyo"} }, { name: "Mei", age: 18, sex: "F", address: { city: "Saitama"} } ];
データの人間的な温かみを損なうわけにはいきませんから、persons を破壊することなく宣言的に書いてみましょう。
const result = persons .filter(p => p.age < 15) .filter(p => p.address.city == 'Tokyo') .map(p => ({name: p.name, gender: p.sex})); // result には [ { "name": "Asahi" , "gender": "F"} ] が入る
このように Array#map や Array#filter などの高階関数系メソッドを使うことによって、「15歳未満の人」「東京に住んでる人」などの条件が明確になり、『取ってきたいデータとはどんなものであればいいか』を書き連ねるだけで所望の処理を記述することに成功しています。
こうしたユースケースは、「関数型っぽくスマートにJS/TSを書こうぜ」的な記事・書籍のどれを見ても、大抵真っ先に紹介されているものです。
しかし、これは果たして本当に「宣言的」と言えるでしょうか。
メソッドチェーンでいくつも処理を繋げてるし、検索条件1つに対してfilter1つを費やさなきゃいけないし、mapのところとかなんかグチャグチャと命令的チックなことやってるし…。
はっきり言って美しくありません。
「宣言的」という言葉を仰々しく使うのであれば、filterやらmapやらをゴチャゴチャ書き連ねるのではなく、最初っから「15歳未満かつ東京に住んでる人」を決め打ちでスパァーッと取得させてほしいものです。
そんな憤りを抱えながらTypeScriptでエセ関数型プログラミングをしている皆さんにオススメしたいのが、こちらの「Declaraoids」というライブラリです(※作者 !== 筆者)。
Declaraoidsを使うと、上のように煩雑で命令的なことをしなくても、なんと1回のメソッドアクセスだけで同じことができるんです!!!!!!
これはもはや宣言的プログラミングを超えた「超・宣言的プログラミング」と言っても過言ではありません!!!!!!!!!!!!!!!!!
const declaraoids = require('./declaraoids'); const result = declaraoids.findNameAndSexAsGenderWhereAgeLessThanXAndAddress_CityEqualsCity(persons, {x: 15, city: 'Tokyo'}); // result には [ { "name": "Asahi" , "gender": "F"} ] が入る
種明かし
はい、皆さん「それはないだろ!」と思いましたよね。私もそう思います。 ここまで宣言的プログラミングについて色々とおかしなイチャモンをつけてしまいましたが、本気で上のような「超・宣言的プログラミング」を布教しようとしているわけではありません。
ここで重要なのは、実は上のコードはちゃんと完動するということです。
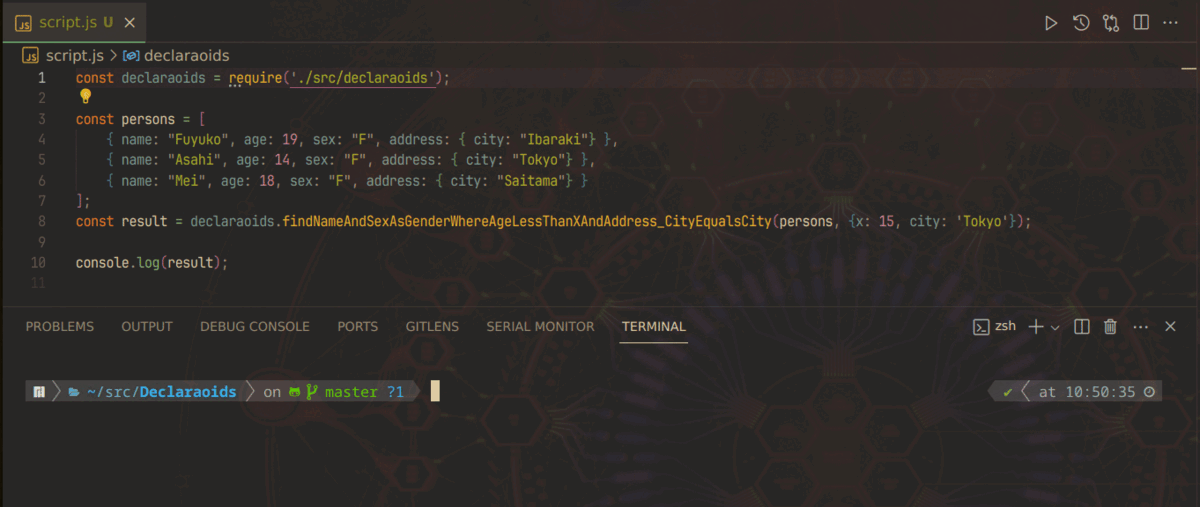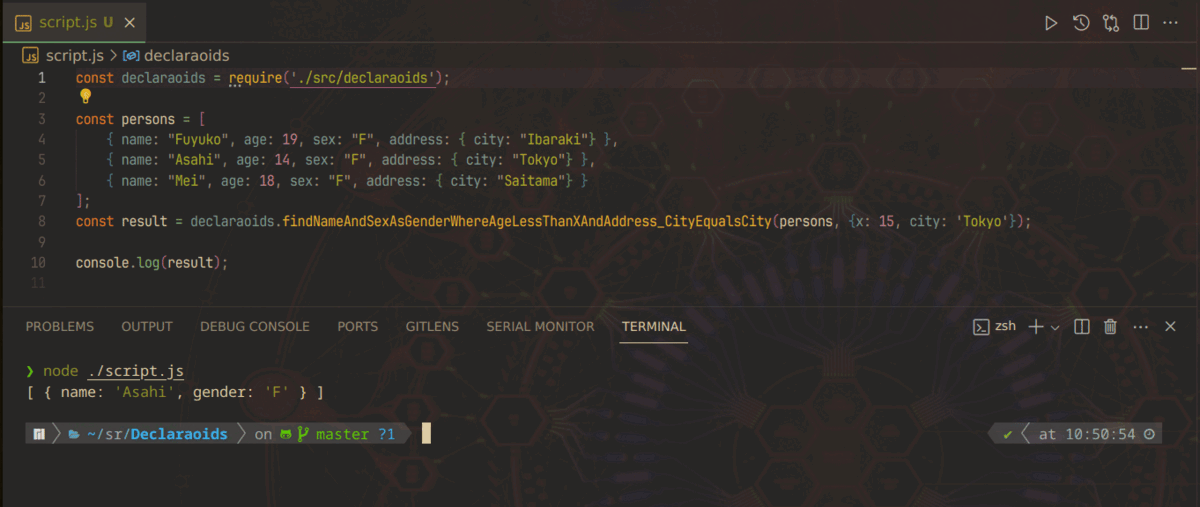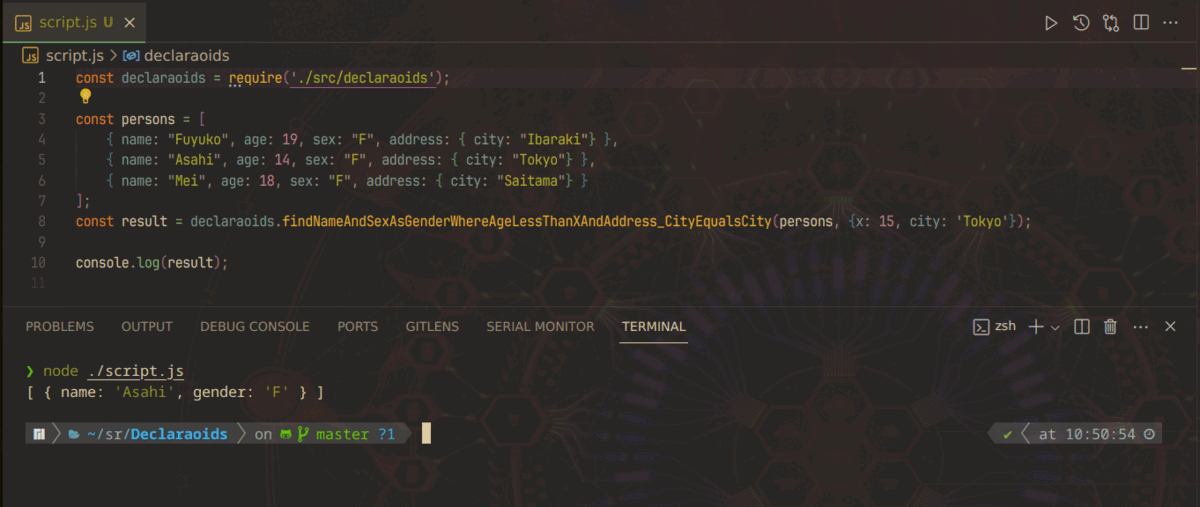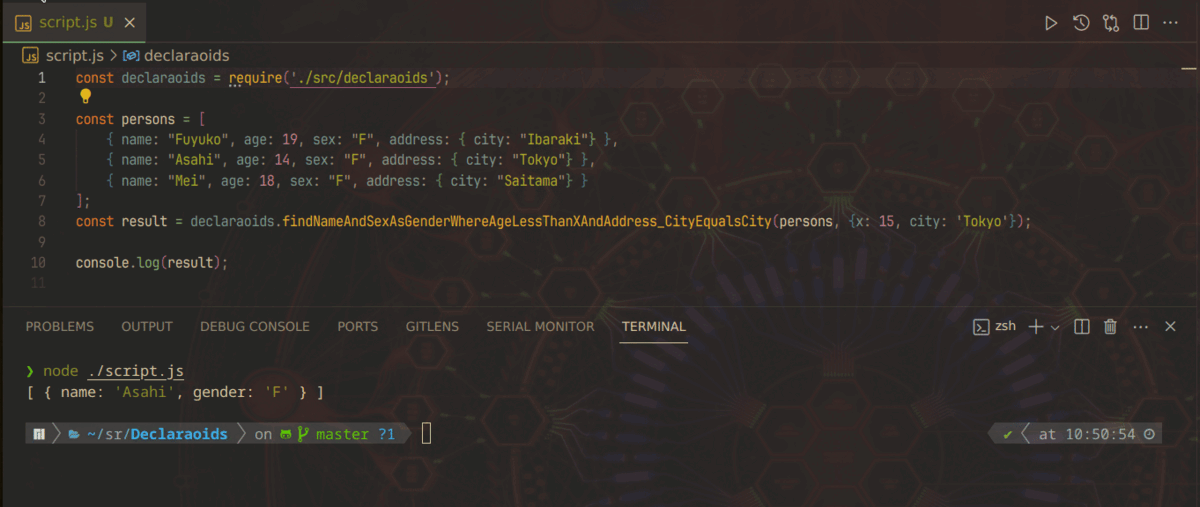
一見すると何かの冗談のようなコードですが、これがどうしてちゃんと動くのか、その原理を確かめていきましょう。
まずは declaroids のモジュールが何をエクスポートしているのかを見てみます。
module.exports = new Proxy({}, { get (target, property) { return finder(property); } });
Proxy という組み込みオブジェクトのインスタンスをエクスポートしているのが分かりますね。
つまり、declaraoids.findNameAndSexAsGenderWhereAgeLessThanXAndAddress_CityEqualsCity() というとんでもないメソッドは、組み込みオブジェクト「Proxy」によって実現されていたのです。
今回の記事の本題はここからです。
Proxy
Proxyとは、ES2015から導入されたJavaScriptの言語機能です。簡単に言うと、JavaScript本来のオブジェクトの挙動を上書きできるという機能です。
もう少し詳しく言うと、あるオブジェクトに対して、特定の操作をした際の挙動をカスタマイズした新しいオブジェクトを作れる機能です。
ただし、どんな挙動でも際限なく上書きできるというわけではなく、カスタマイズできる操作の種類は言語仕様できっちり制限されています(それでも十分に色々なことができますが)。
非常に雑なたとえですが、「getter や setter をハチャメチャに高機能化したもの」というイメージを持つと分かりやすいと思います。
例として、MDN から引用してきたコードを見てみましょう。
// カスタマイズの対象になるオブジェクト const target = { message1: "hello", message2: "everyone", }; // カスタマイズ内容を記述したオブジェクト const handler = { get(target, prop, receiver) { return "world"; }, }; // カスタマイズの実行 const proxyObj = new Proxy(target, handler); // カスタマイズされたオブジェクトは、どんなプロパティアクセスに対しても "world" とだけ返すようになる! console.log(proxyObj.message1, proxyObj.message2); // -> "world", "world" console.log(proxyObj.undefinedProperty); // -> "world"
上の例では、target オブジェクトへ get という操作を行った時の挙動を改造しています。
ここでの改造内容は、『どんなプロパティへのアクセスに対しても "world" という文字列を返す』というものです。
handler オブジェクトは、「何の操作をどのように改造するか」の情報を表すオブジェクトです。
改造内容は handler オブジェクトのメソッドとして記述されます(このメソッドのことを『トラップ』と呼びます)。
この例では get メソッド(get トラップ)に改造内容が記述されていますが、指定するメソッド(トラップ)の名前は「どの操作を改造するか」によって変わります。
また、1つの handler に 2つ以上の異なるトラップを記述する(=異なる2つ以上の操作を同時に改造する)こともできます。
そして、改造元の target オブジェクト・改造内容の handler オブジェクトを組み込みオブジェクト Proxy に渡すと、改造されたオブジェクト proxyObj が作成されるというわけです。
さらに詳しい使い方については、先駆者の方々による様々な解説記事を参照してください。
個人的な所感ですが、Proxyはライブラリやフレームワークを使う時というよりも、作る時に活躍する機能だと思います。 Vue 3 のリアクティビティシステムも、Proxy を使って実装されていることで有名です(詳しい説明は下記リンク先に譲ります)。
しかし、なんとなく「Proxyはこういう風に書く」「Proxyはこんなことに使われている」ということは知っていても、「具体的にどんなことができるのか」という話になるとピンと来ない人もいるのではないでしょうか。 その点において、declaroids はものすごく面白く、考えようによっては教育的な例であると個人的には思います。
改めて、先ほどのエクスポート元のコードを見てみましょう。
var parser = require('./parser'); module.exports = new Proxy({}, { get (target, property) { return finder(property); } }); function finder(query) { var parsed = parser(query); var mapFunc = generateMapFunction(parsed); var filterFunc = generateFilterFunction(parsed); return (array, args) => { return array .filter(filterFunc(args)) .map(mapFunc); } } function generateMapFunction(parsed) { /*... */ } function generateFilterFunction(parsed) { /*... */ }
declaraoids の正体は、get トラップを仕掛けた Proxy オブジェクトです。
README.md 内の "Syntax" 解説 で説明されている通りにメソッド(というかクエリ)を書き、Proxy オブジェクトのメソッドとして呼び出すと、内部的にパーサが走ってクエリを解釈し、その通りにオブジェクトを操作してくれる仕組みになっています。
「こんなんどこで使うねん」というボヤきを聞くことも多い [要出典][誰に?] Proxy ですが、このようなこともできるというお話でした。
頑張って TypeScript で declaraoids に型を付けてみようかとも思っていたのですが、記事の公開日には間に合いませんでした。 もしもうまく行ったら続編として記事にします。
Proxyの欠点と実用性
速度
Proxy オブジェクトの操作は、通常のオブジェクト操作に比べてかなり遅くなることが知られています。
declaraoids にはベンチマーク用コードも同梱されていたので、手元の環境 (Node.js v20.10.0) で実行して計測してみました。
❯ npx mocha test/speed.spec.js Speed comparison Result with list of 50 items Simple filter&map x 7,282,059 ops/sec ±0.78% (81 runs sampled) Simple declaraoids x 486,464 ops/sec ±6.08% (71 runs sampled) Fastest is Simple filter&map Result with list of 100000 items Simple filter&map x 236 ops/sec ±1.24% (85 runs sampled) Simple declaraoids x 126 ops/sec ±1.66% (79 runs sampled) Fastest is Simple filter&map ✓ Simple query (22549ms) Result with list of 50 items Advanced filter&map x 19,447,091 ops/sec ±0.57% (97 runs sampled) Advanced declaraoids x 286,637 ops/sec ±0.49% (97 runs sampled) Advanced declaraoids CACHED x 872,852 ops/sec ±0.31% (96 runs sampled) Fastest is Advanced filter&map Result with list of 100000 items Advanced filter&map x 369 ops/sec ±1.96% (84 runs sampled) Advanced declaraoids x 31.05 ops/sec ±0.43% (55 runs sampled) Advanced declaraoids CACHED x 30.87 ops/sec ±0.27% (54 runs sampled) Fastest is Advanced filter&map ✓ Advanced query (32881ms) Check that they return equal ✓ Simple query ✓ Advanced query 4 passing (55s)
実行環境の違いもあり、declaraoids作者による計測結果とはだいぶ異なる数値が出ていますが、やはりバニラの機能よりも Proxy の方が圧倒的に遅いことが分かります。
速度が重要なアプリケーションでは Proxy を多用すべきでないと思います。
エコシステムについて
Proxy は非常に強力な機能ではあるのですが、強力すぎて ES5 までの機能だけでは再現できません。言い換えると、完全な Polyfill を作ることができません。
一応、Google Chrome の開発チームが Polyfill を公開していますが、 get・set・apply・construct の4種類のトラップにしか対応していません。
declaraoids の場合は get トラップしか使用していないので Polyfill で何とかなりそうですが、一般論として、とても古いブラウザでの動作を未だに保証しなければならないアプリケーションでは Proxy オブジェクトを使うべきではありません(今どきあまりない事とは思いますが)。
TypeScriptとの食い合わせもあまり良くなく、Proxy を乱用すると型が付けられなくなる場合があります。
わかりやすさ
わかりやすさの観点で言えば確実にアウトです。
が、このようなメソッドの動的生成は「メタプログラミング」と呼ばれる重要なプログラミング技法の一種です。
私自身はあまり詳しくないですが、特に Ruby のライブラリではこのような動的メタプログラミングを多用する場合があると聞き及んでいます。
最後に
皆もJavaScriptでメタプログラミング、しよう!
明日は skht777 さんの記事です。
読書メーターとGitHub Actionsで、大学図書館の本を『積読』しよう
この記事は、「LipersInSlums Advent Calendar 2023」第14日目の記事です。
昨日の記事は、ターニャ・デグレチャフさんの「Monadic Parserの俺的理解」でした。
知らない人のために触れておくと、LipersInSlums とは謎の Discord サーバです。 旧 Twitter ヘビーユーザーの計算機オタクがなぜかいっぱい集まっているという特徴があります。住民からは「スラム」と通称されています。
具体的にどんなところがスラム街っぽいのかについては、melovilijuさんの5日目の記事を読めば何となくわかると思います。
はじめに
突然ですが、皆さんは積読してますか?私はしてます。
受験生の頃に神保町の古本市でストレスを紛らわすことを覚えて以降、ろくに読んでない本がまだ大量にあるのになぜか色々な本屋を巡っては、インターンの給与の大半を紙の山に変換するという日々を送るようになりました。
本を渉猟している間の脳内は「面白そうな本がこんなにたくさん並んでるぞ!ここに住みてえ!」という多幸感で満ち溢れているのですが、いざレジに並んでバーコードリーダーの電子音が耳に入ってくると、快楽に代わって絶起時にも似た謎の虚無感が襲いかかってきます。
有料の紙袋を手に退店し、下りエスカレータの手すりに体重を預けているうちに頭をもたげるのは「また買っちゃったな、早く読まなきゃ」という義務感です。 「最近の新刊書は店頭に並んでいるうちに買わなきゃすぐに絶版になるんだからしょうがない!!!」と自己正当化を図りながら自動ドアをくぐり、外の冷たい空気を吸うと、喪失感のいくばくかは充実感へスーッと変換されます。 陰と陽両方の感情を胸に抱きつつ、自宅の床の空きスペースを頭の中で勘定しようとすると、途端に丸善のロゴ入り紙袋が子泣き爺のようにズシリと重量を増し始めるのです。
丸善丸の内本店の店内には、何か人を恍惚とさせるような謎の物質が散布されているのかもしれません。 個人的には大麻よりも先にあちらを法規制すべきだと思います。
なお、新刊書だけでなく古本収集にも手を出している私の本棚は既にキャパオーバーしているため、家族の本棚を間借りしています。 約2年前に行った京都旅行で一番楽しかったレジャーは、日程を丸一日費やしての古本屋巡りでした。 「積読本は謎のエネルギー波を出しており、持ち主が寝ている間に脳を活性化させてくれる」なんて話もありますが、少なくとも財布と精神の健康にはまるでよろしくないと思います。
そんな書痴気味の私にとってなくてはならないのが、蔵書管理ツールです。 読んだ本や積読本が多くなってくると、ダブリ購入防止のため蔵書を良い感じに管理したくなってくるものですよね。 私は4年ほど前から「読書メーター」というWebサービスを使って蔵書・読書状況を管理しています。
私が読書管理の中で最も重視している営みは、今ある蔵書の管理というよりも『読みたい本の管理』です。 書店の棚・旧Twitterのタイムライン・面白そうな授業のシラバスなどを見ていると、面白そうな雰囲気の本に思いがけず出会うことがしばしばあります。 そんな時はいわばToDoリストのような感覚で、読書メーターを開いて『読みたい本』に登録しています。 この習慣を4年ほど続けているうちに、いつの間にか『読みたい本』が800冊を数えるようになりました(2023年12月現在)。
ここで話はB1の冬休み(『読みたい本』がまだ300冊くらいだった頃)に遡ります。 その頃の私は、読書メーターだけでは『読みたい本』が身近な図書館に置いてあるかが分からないという深刻な悩みを抱えていました。
当時は何度目かの緊急事態宣言が明けて、キャンパスへの入構規制が少し緩和されていた頃です。
入学以来初めて大学図書館をそこそこ自由に使えるようになったことで、「この本、大学図書館に置いてあったのかよ…Amazonから自腹で買う必要なかったじゃん…」 という悲劇にたびたび見舞われるようになっていました。
まして高額な専門書ともなると、自分に合わない本と知らずに買ってしまった時の損失は本当にバカになりません(金銭的にも精神的にも)。合うかどうかも分からないのに高額な本を買う方がバカだと? うるせぇ〜!!
そもそも、図書館の資料購入費や維持管理費は(少なくともある程度は)学費で賄われているはずです。言い換えれば、図書館の本は実質学生の金で買われたようなもの。 ということは、実質的には私の所有物…すなわち私の積読本と言っても全く過言ではないでしょう。 何万冊もの積読本が所有しているにも拘らず、その内容を自分では全く把握できていない! なんと嘆かわしいことでしょう……。これこそ、技術の力でどうにかすべきです!
ともかく、そうなると当然こういうモチベーションが湧いてきます。
#stepney141のメモ
— ゆみや (mstdn.maud.ioにもいます) (@stepney141) 2021年2月21日
bookmaterから読みたい本を取得して、大学図書館に所蔵されてないか自動で確認してくれるツールがほしい
というわけで、そういうツールを自分で作って現在まで運用を続けている話について、B1~B2の頃の自分を振り返る意味も込めて書いてみます。
TL;DR
あらかじめお断りしておくと、技術的に高度なことは一切せず、あるものを素直に組み合わせているだけです。
- 言語は JavaScript → TypeScript (+ Node.js)
- いろんな WebAPI を組み合わせ、書誌情報と所蔵の有無を調べている
- GitHub Actions 上で稼働している
- データは CSV ファイルとして GitHub で管理

なお、完成品はこちらです。 github.com
やったこと
技術選定
求めている機能はだいたいこんな感じでした。
- 読書メーターの『読みたい本』が大学図書館にあるかどうかをリスト化したい
- 書名だけじゃなく、著者とか出版年とかも見れるようにしたい
- 図書館の中でもスマホでパッと見れるようにしたい
- 「大学にある本」「大学にない本」を分けて見れるようにしたい
やるべきことはこんな感じです。
1. 読書メーターから『読みたい本』の情報をエクスポートする
読書メーターから直接『読みたい本』の情報を出力できれば良いのですが、読書メーターにそうした機能は備わっていません。 したがって、読書メーターをスクレイピングして『読みたい本』の情報を自力で回収する必要があります。
当時の私は Node.js と puppeteer を使った Web E2E テストを書いて給料を貰っていたので、自然な発想として、ここでも使い慣れた puppeteer を使うことにしました。 なお、作った当時は生の JavaScript で書いていましたが、今年に入ってから TypeScript で全面的に書き直しました。
まず、読書メーターから具体的に何の情報を取ってくるべきかという点が重要です。 DevTools で読書メーターの『読みたい本』一覧ページの中身を確認してみると、次のようになっていました(画像は2023年12月撮影)。

ここから個別の本を識別できそうな要素を選び、なんらかの方法で対応する本の書誌情報を取ってくることにしました。 書名は途中までしか表示されないので、使えそうな情報は Amazon 商品ページへの外部リンク・個別書籍ページへの内部リンクに限られます。
Amazon の商品情報を直接取得できる WebAPI は一応存在するようですが、どうも Amazon と連携して EC サイトやら何やらを作りたい事業主のためのサービスらしく、利用条件が厳しかったため断念しました。
Amazon の商品ページを直接スクレイピングして商品情報を取ってくるという手もありますが、手間が増えるので一旦保留。

しばらく DevTools をグッと睨んでいたところ、Amazon への外部リンク URL に ASIN コードが含まれていることに気づきました。
前述したように、ASINコードとは Amazon における商品の識別コードです。ASINコードの命名規則は公表されていませんが、紙の書籍商品ではISBN-10コードがそのまま ASIN コードとして扱われることが知られています(Kindle 電子書籍には紙書籍版と異なるASINコードが採番されます)。 つまり、紙の書籍であれば、読書メーターの URL 文字列を正規表現に食わせるだけでその本の ISBN をゲットできるということです。 ISBN さえ分かれば、何らかの WebAPI を使って書誌情報もゲットできそうですね。Amazon の商品ページを直接読むよりも明らかに簡単そうです。
万が一、アカウントをBANされたり神奈川県警に逮捕されたりしたら困るので、読書メーターの利用規約も確認することにしました。 第9条は「故意に本サービスのサーバ又はネットワークへ著しく負荷をかける行為(14号)」および「当社又は、第三者の著作権、商標権などの知的財産権を侵害する行為、又は侵害するおそれのある行為(18号)」を禁じています。 しかし、サービスに負荷をかけない範囲でのスクレイピング行為は禁じていません。また、取得しようとしているのは単なるURL文字列なので、誰かの知的財産権を侵害することもありません。
読書メーターでは同じ出版物であっても紙の書籍版と Kindle 版とでページを区別しているため、『読みたい本』に紙書籍版ではなく Kindle 版を誤登録してしまいやすい構造になっています。 このため、ツールを動かし始めた当初は、Kindle 版の ASIN コードのまま書誌情報を検索しようとしてしまい「そんな本はねえよ」とエラーを吐かれる事象が頻発していました。
ただし、ツールを動かし始めてからしばらくして読書メーターの検索機能が改修され、紙書籍版が優先的に上位に来るようになったため、この問題に見舞われることは少なくなりました。
読書メーター公式ブログ — ブラウザ版 書誌検索オプション アップデートのお知らせ
2. 書誌情報を取ってくる
ISBN から書誌情報を取得する WebAPI には、主に以下のものがあります。 どれも一長一短なので、私のコードではこれらを組み合わせて使用しています。
本1冊の書誌情報は下のBook型のオブジェクトとして管理し、APIを叩きながらBookオブジェクトを更新する形になっています。
Book は BookList に蓄積されていき、最終的に BookList の中身をCSV形式で出力して処理を終えます。
後述する問題から、BookListオブジェクトの主キーとしては、ISBNではなく読書メーターのURLを使っています。
type Book = { bookmeter_url: string; isbn_or_asin: ISBN10 | ASIN | null; book_title: string; author: string; publisher: string; published_date: string; central_opac_link: string; mathlib_opac_link: string; } & { [key in ExistIn]: "Yes" | "No"; }; type BookList = Map<string, Book>; type ExistIn = `exist_in_${CiniiTargetOrgs}`; type CiniiTargetOrgs = (typeof CINII_TARGET_TAGS)[number]; const CINII_TARGET_TAGS = ["Sophia", "UTokyo"] as const;
ISBNを主キーとして使うことの問題
日本の出版業界におけるISBNの運用状況は、はっきり言って非常にいい加減です。この問題の大変わかりやすい説明として、以下の一連のツイート群を提示しておきます。
「ISBNで本は管理できるのに何故わざわざ図書館でのデータとか作らなきゃいけないの?」という意見を聞いたことがありますが。
— 庫ノ林 (@konobayashi) 2022年1月29日
理由の一つは、「ISBNは万能じゃないから」。
先週、受け入れた本は、初版と改訂版のISBNが同じ。😰
番号を使い回したり、版違いを納本しない出版社はわりとあります。😭
勤務館サイトのTOP画面で、新しく受け入れた資料を「新着資料」として表紙画像付きで紹介しているんですが。
— 庫ノ林 (@konobayashi) 2022年1月29日
ISBNが一緒だと、〝新しい資料〟ではなく複本扱いになってしまうようで、新規に受け入れた改訂版の情報が出ませんでした。😭
対策、考えなくちゃ…。🤔
同じ出版社の別々の本に同じISBNがついていることに気づいた図書館員が問い合わせたところ電話に出た出版社の人が「ごめんなさい!私が!私がまちがえたんです!」と告白したという話を聞いたことがある。 https://t.co/kjPfay96Bc
— てこぺん (@tecopen) 2022年1月29日
数年前に出た小流通本で、裏表紙に別の出版社の全く別の本のISBNが印刷されていたことがあった。なんでそんなことが起こったのかはわからないけど、後で訂正シールが送られてきた。
— 猫の泉 (@nekonoizumi) 2022年1月29日
ISBN使いまわしで一般的な影響が大きいのは、昔の岩波文庫かなあ。翻訳もので、改訂どころか"翻訳者が変わっても"同一ISBNを使いまわしていたことがあった。翻訳だけでなく校訂とかでも。また、校訂・翻訳は同一でも改版でページ数が増えてずれても同一ISBNの例もあるので引用にも注意が必要。
— 猫の泉 (@nekonoizumi) 2022年1月29日
ISBN使いまわしレベルが極まっているのは楽譜出版界隈。楽譜出版はそもそも出版書誌データ自体がそろいにくいのに、同一タイトル同一ISBNで時々収録楽曲を入れ替えるし、デザインも変えるし、追うのが困難すぎる。出版年で判断するしかないという。
— 猫の泉 (@nekonoizumi) 2022年1月29日
上のツイートでも触れられていますが、2016年には岩波書店が同じ本の旧訳・新訳でISBNを使い回していることが判明し、Twitterの読書趣味界隈(+プログラマ界隈の一部)で問題になりました。
stonebeach-dakar.hatenablog.com
こうした問題のため、本当はISBNを書誌情報の主キーとして実用することはできません。
しかしそれにもかかわらず、書誌情報を WebAPI として取ってくる際は ISBN を実質的な主キーとして用いざるを得ません。 そのため、本ツールでは前回の出力結果を活用できず、「実行する度に毎回全ての書誌情報を新しく取ってくる」という効率の悪い実装を強いられる状況になっています(同じ API に同じ ISBN をリクエストしても、返ってくる書誌情報がいつも同じとは限らず、しかも変化が起こるタイミングはこちらから観測できないため)。
OpenBD
みんな大好き株式会社カーリルと、出版業界団体の「一般社団法人 版元ドットコム」が共同で提供している書誌情報APIです。 非常に多様な書誌情報を提供しているのが魅力的です。
最近の本の情報は8割方ここで取れますが、古い本・一部の出版社の本は網羅されていない場合があります。 また、今年になって書誌情報の有力な提供元(別の出版業界団体)と深刻な仲違いをしたらしく、書籍の網羅率や取得可能な書誌情報の量が以前よりも減っています。
6/5から版元ドットコムのデータ更新が不安定になって、少し後にJPROからの新刊・近刊の書誌データ配信についてトラブルになっていて配信停止されたという話が出ていたけど、JPROとだいぶこじれていたのだな……https://t.co/nXblRDSOWphttps://t.co/fnKPRQOTHX
— 猫の泉 (@nekonoizumi) 2023年7月25日
このAPIの最大の特徴は、「全件取得やデータ同期を推奨するAPI設計(大量アクセス対応)」を謳っていることです。
運営元のお言葉に甘えて、1回のリクエストで『読みたい本』全ての書誌情報を一度に検索する贅沢な使い方をしています。
const bulkFetchOpenBD = async (bookList: BookList): Promise<BiblioInfoStatus[]> => { const bulkTargetIsbns = [...bookList.values()].map((bookmeter) => bookmeter["isbn_or_asin"]).toString(); const bookmeterKeys = Array.from(bookList.keys()); const response: AxiosResponse<OpenBdResponse> = await axios({ method: "get", url: `https://api.openbd.jp/v1/get?isbn=${bulkTargetIsbns}`, responseType: "json" }); const results = []; for (const [bookmeterURL, bookResp] of zip(bookmeterKeys, response.data)) { if (bookResp === null) { //本の情報がなかった const statusText: BiblioinfoErrorStatus = "Not_found_in_OpenBD"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; results.push({ book: { ...bookList.get(bookmeterURL)!, ...part }, isFound: false }); } else { //本の情報があった const bookinfo = bookResp.summary; const part = { book_title: bookinfo.title ?? "", author: bookinfo.author ?? "", publisher: bookinfo.publisher ?? "", published_date: bookinfo.pubdate ?? "" }; results.push({ book: { ...bookList.get(bookmeterURL)!, ...part }, isFound: true }); } } return results; };
上述の通り、OpenBDだけでは『読みたい本』全ての書誌情報を得ることができないため、後述する他サービスからの情報で不足分を補完しています。
国立国会図書館サーチ
さすがに国会図書館だけあって、ISBN付きの和書なら十中八九ヒットします。 が、かつてのWeb2.0時代の遺産というべきか、レスポンスがXML形式です。私はfast-xml-parserでパースしています。
const fetchNDL: FetchBiblioInfo = async (book: Book): Promise<BiblioInfoStatus> => { const isbn = book["isbn_or_asin"]; //ISBNデータを取得 if (isbn === null || isbn === undefined) { //有効なISBNではない const statusText: BiblioinfoErrorStatus = "INVALID_ISBN"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; return { book: { ...book, ...part }, isFound: false }; } // xml形式でレスポンスが返ってくる const response: AxiosResponse<string> = await axios({ url: `https://iss.ndl.go.jp/api/opensearch?isbn=${isbn}`, responseType: "text" }); const json_resp = fxp.parse(response.data) as NdlResponseJson; //xmlをjsonに変換 const ndlResp = json_resp.rss.channel; //本の情報があった if ("item" in ndlResp) { // 該当結果が単数か複数かによって、返却される値がObjectなのかArray<Object>なのか変わる。 // fast-xml-parserの設定をいじれば多分もっとスマートにできると思うが、とりあえず目的を達成するにはこれだけ判定すれば十分。 // 面倒なので、該当件数に関わらず配列の先頭だけをチェックしておく const bookinfo = Array.isArray(ndlResp.item) ? ndlResp.item[0] : ndlResp.item; const part = { book_title: bookinfo["title"] ?? "", author: bookinfo["author"] ?? "", publisher: bookinfo["dc:publisher"] ?? "", published_date: bookinfo["pubDate"] ?? "" }; return { book: { ...book, ...part }, isFound: true }; //本の情報がなかった } else { const statusText: BiblioinfoErrorStatus = "Not_found_in_NDL"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; return { book: { ...book, ...part }, isFound: false }; } };
Google Books
みんな大好きGoogleが提供しているGoogle BooksというサービスのAPIです。 developers.google.com
1日に1000回までという利用上限があるため、使いどころをかなり考えて叩く必要があります。 今のところ、OpenBDや国会図書館サーチでは手薄になっている洋書の情報を補う目的で採用しています。
const fetchGoogleBooks: FetchBiblioInfo = async (book: Book): Promise<BiblioInfoStatus> => { const isbn = book["isbn_or_asin"]; if (isbn === null || isbn === undefined) { //有効なISBNではない const statusText: BiblioinfoErrorStatus = "INVALID_ISBN"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; return { book: { ...book, ...part }, isFound: false }; } //有効なISBNがある const response: AxiosResponse<GoogleBookApiResponse> = await axios({ method: "get", url: `https://www.googleapis.com/books/v1/volumes?q=isbn:${isbn}&key=${google_books_api_key}`, responseType: "json" }); const json = response.data; if (json.totalItems !== 0 && json.items !== undefined) { //本の情報があった const bookinfo = json.items[0].volumeInfo; const part = { book_title: `${bookinfo.title}${bookinfo.subtitle === undefined ? "" : " " + bookinfo.subtitle}`, author: bookinfo.authors?.toString() ?? "", publisher: bookinfo.publisher ?? "", published_date: bookinfo.publishedDate ?? "" }; return { book: { ...book, ...part }, isFound: true }; } else { //本の情報がなかった const statusText: BiblioinfoErrorStatus = "Not_found_in_GoogleBooks"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; return { book: { ...book, ...part }, isFound: false }; } };
楽天ブックスAPI
みんな大好き楽天が提供している楽天ブックスというサービスのAPIです。 ECサイトの商品検索APIなので、和書だけでなく雑誌やCDや洋書にも対応しているのが強みです。
現在のところは上述の3つで十分な情報を取れているので採用していませんが、そのうち雑誌検索用に使おうかと考えています。
高速化のために
ここまで述べてきた通り、このツールは何種類もの WebAPI を合計で数百回ほど叩くことによって実現されています。
しかし、何も考えず直列的に API を叩くと、読書メーターの走査開始からCSVファイルの出力までに30分は掛かってしまいます(リクエスト1回につき1~2秒のインターバルを置くと、さらに時間がかかります)。 そのため、こちらの記事を参考に複数のPromiseを同時並行で処理しています。
これが功を奏し、APIリクエストのインターバル込みでも12~13分で処理を終わらせられるようになりました。
const fetchBiblioInfo = async (booklist: BookList): Promise<BookList> => { const mathLibIsbnList = await configMathlibBookList("ja"); const updatedBookList = await bulkFetchOpenBD(booklist); const fetchOthers = async (bookInfo: BiblioInfoStatus) => { let updatedBook = { ...bookInfo }; // NDL検索 if (!updatedBook.isFound) { updatedBook = await fetchNDL(updatedBook.book); } await sleep(randomWait(1500, 0.8, 1.2)); // GoogleBooks検索 if (!updatedBook.isFound) { updatedBook = await fetchGoogleBooks(updatedBook.book); } await sleep(randomWait(1500, 0.8, 1.2)); // CiNii所蔵検索 for (const library of CINII_TARGETS) { const ciniiStatus = await searchCiNii({ book: updatedBook.book, options: { libraryInfo: library } }); if (ciniiStatus.isOwning) { updatedBook.book = ciniiStatus.book; } } // 数学図書館所蔵検索 const smlStatus = searchSophiaMathLib({ book: updatedBook.book, options: { resources: mathLibIsbnList } }); if (smlStatus.isOwning) { updatedBook.book = smlStatus.book; } booklist.set(updatedBook.book.bookmeter_url, updatedBook.book); }; const ps = PromiseQueue(); for (const book of updatedBookList) { ps.add(fetchOthers(book)); await ps.wait(6); // 引数の指定量だけ並列実行 } await ps.all(); // 端数分の処理の待ち合わせ console.log(`${JOB_NAME}: Searching Completed`); return new Map(booklist); };
3. 大学図書館の所蔵情報を取ってくる
日本語の学術論文をネットで検索したことがある人なら、国立情報学研究所の運営する「CiNii」というデータベースを一度は使ったことがあるでしょう。 その一部である「CiNii Books」の WebAPI を使うと、大学図書館の蔵書を好きなクライアントから検索することができます。
レスポンスがちゃんとJSONで返ってくるのは嬉しいところですが、重要な個人情報(本名・所属元)を開示しないと利用申請できないのは少しマイナスポイントかもしれません。
CiNii では図書館を区別するための情報として、大学単位で割り振られる「機関ID」と、大学内にある個別の図書館施設ごとに割り振られる「図書館ID」というコードを持っています。 APIを叩く際、これらの少なくとも一方を含めてリクエストしてあげると、指定した本が狙った図書館に所蔵されているかどうかを調べることができます。 コードの一覧は、CiNii の基盤となっている「目録所在情報サービス」というシステムの公式サイトから確認できます。
なお、弊学には CiNii に情報を公開していない「数学図書室」という施設があるのですが、こちらの所蔵検索はあまり良い感じで実現できていません。 今のところ、司書さんにお願いして蔵書一覧のPDFファイルを公式サイトに掲示してもらい(サイト容量の問題でPDFじゃないとアップロードできなかったらしい)、それをpdfdataextractというnpmパッケージで無理やりパースする形を取っています。元ファイルの問題で誤認識が多いのが目下の課題です。
ともあれ、上のような手段で大学に所蔵されている本だと分かったら、大学図書館のOPACリンクをCSVファイルに出力します。
2024/01/26追記:「CiNiiには登録されていないが、大学図書館のOPAC上では登録されている本」が、少なからず存在することに気づきました。一例を挙げておきます。
この問題のため、CiNiiだけでは正確な所蔵情報を取ってくることができません。対策として、CiNiiの所蔵検索で見つからなかった場合は、大学図書館のOPACに直接アクセスしてページの実在をチェックするようにしました。
const searchCiNii: IsOwnBook<null> = async (config: IsOwnBookConfig<null>): Promise<BookOwningStatus> => { const isbn = config.book["isbn_or_asin"]; //ISBNデータを取得 const library = config.options?.libraryInfo; if (library === undefined) { throw new Error("The library info is undefined"); } if (isbn === null || isbn === undefined) { //異常系(与えるべきISBN自体がない) const statusText: BiblioinfoErrorStatus = "INVALID_ISBN"; const part = { book_title: statusText, author: statusText, publisher: statusText, published_date: statusText }; return { book: { ...config.book, ...part, [`exist_in_${library.tag}`]: "No" }, isOwning: false }; } // const title = encodeURIComponent(config.book["book_title"]); const url = `https://ci.nii.ac.jp/books/opensearch/search?isbn=${isbn}&kid=${library?.cinii_kid}&format=json&appid=${cinii_appid}`; const response: AxiosResponse<CiniiResponse> = await axios({ method: "get", responseType: "json", url }); const graph = response.data["@graph"][0]; if ("items" in graph) { //検索結果が1件以上 const ncidUrl = graph.items[0]["@id"]; const ncid = ncidUrl.match(REGEX.ncid_in_cinii_url)?.[0]; //ciniiのURLからncidだけを抽出 return { book: { ...config.book, [`exist_in_${library.tag}`]: "Yes", central_opac_link: `${library.opac}/opac/opac_openurl?ncid=${ncid}` //opacのリンク }, isOwning: true }; } else { //検索結果が0件 // CiNiiに未登録なだけで、OPACには所蔵されている場合 // 所蔵されているなら「"bibid"」がurlに含まれる const opacUrl = `${library.opac}/opac/opac_openurl?isbn=${isbn}`; const redirectedOpacUrl = await getRedirectedUrl(opacUrl); await sleep(randomWait(1000, 0.8, 1.2)); if (redirectedOpacUrl !== undefined && redirectedOpacUrl.includes("bibid")) { return { book: { ...config.book, [`exist_in_${library.tag}`]: "Yes", central_opac_link: opacUrl }, isOwning: true }; } return { book: { ...config.book, [`exist_in_${library.tag}`]: "No" }, isOwning: false }; } };
4. デプロイして定時実行する
以下の理由から、バックエンド・フロントエンドの両方を GitHub に頼ることにしました。
- 人類の根源的かつ本能的な欲求として、高頻度で更新されるテキストデータの差分は Git で管理したい。
- GitHub には様々な条件をきっかけに処理を自動で実行してくれる GitHub Actions という機能がある。
- GitHub には CSV ファイルを良い感じの表形式にレンダリングしてくれる機能がある。検索機能までついている。
また、単なる『読みたい本の一覧』1つだけでは情報が多すぎて小回りが効きません。 そのため「q」というCSV操作ツールで場合分けし、大学にある本・ない本ごとに別々のCSVファイルを追加で作成しています。
#!/bin/bash source_from="FROM ./bookmeter_wish_books.csv" base_columns="isbn_or_asin, book_title, author, publisher, published_date" filter_book_title_error="(book_title NOT LIKE 'Not_found_in%' AND book_title NOT LIKE '%INVALID_ISBN%')" q -d, -O -H "SELECT $base_columns \ $source_from \ WHERE exist_in_Sophia='No' AND $filter_book_title_error"\ > not_in_Sophia.csv q -d, -O -H "SELECT $base_columns, central_opac_link, mathlib_opac_link \ $source_from \ WHERE exist_in_Sophia='Yes'"\ > in_Sophia.csv
毎週日曜日の午前0時・水曜日の午後0時になると GitHub Actionsの cron 機能が発火し、これらの一連の処理を実行します。 更新されたCSVファイルはそのまま GitHub リポジトリにコミットされます。
出力した『読みたい本』リストを眺めてみる
現在在籍している大学と今度進学する大学院とで、どれだけ図書館の収蔵内容が違うのか見比べてみました。
まず、大学院にあって学部にない本がこちら。
ジャンルを問わず、全体的に大学院の方が蔵書がキメ細やかであることがわかります。
一方で「学部にあって大学院にない本」がこちら。
「大学の規模から言っても今の大学にしかない本なんてほとんどないだろう」と思っていましたが、意外に多くて驚きでした。全体的に、思想史(の中でもニッチな西洋神秘主義関連の分野)・文化史・ルポルタージュ系の本が目立ちますが、数学書や新刊技術書でも意外と漏れがあるようです。 春休みは図書館に籠もって、このリストにある本を中心に積読を消化していきたいと思います。
さて、現在の大学にも進学先の大学院にもない本もかなりありました。というかこれが一番多いんじゃないか?
当たり前と言えば当たり前ですが、サブカル系の本はどちらの図書館にも所蔵されていないことが分かります。
ただ『行動経済学の逆襲』がないのはおかしくない? ノーベル賞受賞者の本やぞ。ISBNの問題かしら…。
あと『楽器の物理学』が今の大学にないのもおかしいって。こないだ中央図書館の9Fで見たぞ。やっぱりISBNの問題かなあ…。 ISBNの問題でした(丸善出版の旧版とシュプリンガー・ジャパンの新版でISBNが異なっていたせいだった)。
今回の記事には間に合いませんでしたが、クラスタリングとかで読みたい本の傾向を分析してみるのも面白いかもしれません。
今後の課題
ISBNのない出版物はどうする?
以下のような本にはISBNがないため、現行のシステムでは書誌検索の対象にできません。
- 雑誌
- 80年代以前の古い本(ISBNのなかった時代の本)
- Kindle本
ASINコードとかJANコードとかの情報を使って、どうにかうまいこと書誌検索できたらいいなあと思っていますが、そもそもどこから情報を取ってこれるのか全く分かっていません。 良い感じの方法をご存じの方がいらしたら教えてください。
Amazonのほしい物リストと連携させたい
欲しい物が多いからには、やっぱり他人に買ってもらいたいですよね。 何とは言いませんが、ちなみに私は先月末に誕生日を迎えました。
最後に
みんなも積読、しよう!!!
明日はstepney141さんの「このJavaScriptライブラリがキモい(褒め言葉)・2023」です。どんな記事なのか楽しみですね。
セキュリティ・キャンプ2022全国大会 (X3: ハードウェア魔改造ゼミ) 参加記
セキュリティ・キャンプ2022全国大会の開発コース「X3: ハードウェア魔改造ゼミ」に参加してきました。 開発中に色々と難しい箇所にも遭遇しましたが、ゼミの目標をなんとか達成することが出来たので、参加記を公開します。
何をしたか
セキュリティ・キャンプとは、経済産業省の外郭団体である独立行政法人「情報処理推進機構(IPA)」及び一般社団法人「セキュリティ・キャンプ協議会」が主催している、若年IT人材の発掘・育成事業として行われる無償のサマースクールです。 暗号・Web技術・低レイヤ開発・ハードウェア解析などの多様な分野の中から自分が希望するコースに応募し、その分野の専門家から指導を受けつつ、事前に設定されたカリキュラムに沿って座学や開発・実装を行います。
参加者は書類選考によって決定されます。 参加希望者は興味のあるコースを最低1つ選んで、そのコースで扱う分野についてあらかじめ与えられている応募課題を提出します。 この課題の出来具合が一定の水準を満たしていると、選考通過となり、参加資格を得ることができます。
例年は毎年8月に対面合宿形式で5日間の日程で開催されていますが、2020年からはオンライン開催が続いています。 去年・一昨年は講師・チューター・受講生全員がオンラインで参加し、数ヶ月の開催期間を取ってゆっくりと講義を進めていたそうです。 しかし今年はやや特殊なハイフレックス方式で開催され、講師・チューター陣だけは例年通り対面宿泊形式で、一般の受講生のみオンラインで参加するという形でした。 このため、開始時間・食事休憩・終了時間はどちかというと宿泊場所の時間の都合に合わせてあるような感じになっていました。
私が選考に通過したX3ゼミは「開発コース」と呼ばれるラインナップに属し、講師やチューターの指導の下、自分の手で実際に何かを開発・実装することに主眼を置くカリキュラムになっています。 中でもX3ゼミの開発内容は、市販の無線ルーターを「魔改造」して、スマホから操作できるラジコンに作り変えてしまおう!という一際異色なものです。 この過程で、
...というように低いレイヤから高いレイヤに上がっていくようにして開発を進め、様々な技術レイヤの基本的な内容に広く触れることがX3ゼミの目標です。 セキュキャンでは「特定の技術レイヤーについて狭く深く学ぶ」というカリキュラムが組まれることが多いですが、X3ゼミの講義内容はそれとは対照的になっています。
一見すると「セキュリティと走るルーターに何の関係があるの?」と思われてしまいそう*1ですが、X3ゼミでこのようなカリキュラムが組まれている背景には、
- 「セキュリティ」をやるからこそ、全てのレイヤに自分で触れて知っておくことが重要
- なぜなら「悪意ある攻撃」のアプローチは幅広いので、全てのレイヤに対して様々な攻撃手法が存在するから
- ソフトウェアの脆弱性を突いたり暗号を破ったりするだけがセキュリティではなく、例えば「マシンやパソコンケースの分解・物理的破壊」「コンピュータから漏れ出る電波の傍受」「乱数の生成方法」なども相手にしなくてはならない
- セキュリティ以外のものづくりや趣味開発においても、幅広いレイヤに触れた経験は役に立つ
...という、講師の末田さん(puhitakuさん)の意図が込められています。
短く言うと僕の講義の意図は「全レイヤーに触った体験を、後に技術を掘る道しるべにして欲しい」という当たり障りのない日本語になってしまう
— Takumi Sueda (@puhitaku) 2022年8月12日
全レイヤーに触れる過程の気付きが有機的だったことの片鱗が受講生のツイートから見えるあたり、目標は達成できたなという実感がある #seccamp
この他にも、協賛企業の社員の方々から事業内容について直接ご説明を頂くイベントや、受講生同士で今後も繋がろうという趣旨で行われる「グループワーク」、さらには参加者有志によるLT大会なども開かれ、期間は短いながらもかなり盛り沢山の日程が組まれていました。
技術的構成
※本講義は電波法の規定とその抵触リスクについて十分に配慮した上で改造を行っているという、講師からの案内がありました。また、講義内でも技術基準適合証明と電波法についての解説と注意があり、これを踏まえて作業を行いました。


X3ゼミで制作するラジコンルーターシステム全体の肝になるのは、香港の GL.iNet が販売している小型無線ルーター「GL-MT300N-V2」です。 本機種の特徴は以下の記事にまとまっています。
機種名をネットで検索するとこの記事以外にも様々なレビュー記事がヒットしますが、どの記事も共通して挙げていた本機の最大の特徴は「OpenWrtを搭載していること」です。 OpenWrt とは、ルーター用などの組み込み機器のファームウェア用途向けに開発されている Linux ディストリビューションで、いわゆる組み込みLinuxと呼ばれるものの一つです。 本機は最初から OpenWrt で出来たファームウェアを搭載している状態で技適を取得していることから、無線通信に関する部分をいじらずにシングルボードコンピュータの要領でソフトウェアを導入できるので、ラジコンルーターに「魔改造」しても電波法の規定には抵触しないのです。
この小型ルーター「GL-MT300N-V2」に入っている OpenWrt 上で Python 製のREST APIサーバを動かします(計算資源の制約などを考慮し、処理系には MicroPython を使用します)。 スマートフォンやパソコンから REST API を叩くと、HTTP リクエストを受け取った REST APIサーバがシリアル通信で Arduino Nano Every に命令を飛ばします。 ここで Arduino には予め、シリアル通信の内容に従ってモータードライバに電圧を加えるような処理を書き込んでおきます。 こうすることで、端末から飛ばした操作指示に応じてモーターが動いて、タイヤが前後に回るという一連の仕組みが完成するわけです。
GL-MT300N-V2 のルーターとしての機能をそのまま使用することで、スマートフォンやパソコンなどの各種端末からの無線操作を容易としているところが特に面白いと思います。
私のバックグラウンド
- 学部での専攻:数理経済学
- 趣味・(実質的な)副専攻:CSおよびゲーム情報学、特にアブストラクトゲームのプログラミングと解析
- 主な技術スタック:JavaScript/TypeScript を用いたフロント/バックエンド開発、初歩的な数値解析
はい、高いレイヤや抽象的なレイヤに経験がかなり偏っていますね。 組み込み分野のような低いレイヤ層の開発には以前から強い興味はあったものの、他のタスクで忙しく手を出せずにいました。
電子工作についてはほとんど触れたことがなく、高校物理の電磁気分野以外の知識は皆無です。 この記事を書く前に同じX3コースの受講生の@771-8bitさんによる参加記も拝読したのですが、電気回路周りの思考の道筋を見ていて「こういう事項を考えたり調べたり実行したりする背景にはどういう目的意識があるんだろう...?」という疑問でいっぱいになってしまい、レベルの違いを実感しました。 この辺の「自分が知らない分野での思考の道筋の立て方」については今回かなり色々な学びを得たので、本記事の最後にまとめて記述します。
# 先週までのハードウェア経験値
— ゆみや (@stepney141) 2022年8月10日
- 人生でハンダ付けした総数: 先週までは高々4, 5回
- 人生でブレッドボードを手に取った総回数: 1桁
- 人生でブレッドボードを使って回路製作をした総回数: 0回
- 人生で基板キットを使った総回数: 0回
時系列
開発コースの内容については、箇条書きの日記形式で当時の思考を再現します。
8/7 (0日目)
開講式前日です。車体は事前に製作しておいた方が時間に余裕が出来るという話が講師のpuhitakuさんから事前になされていたので、私はこの日に車体の製作を開始しました(この日だけでは終わりませんでした)。 人によるかと思いますが、自分の場合車体の工作には割と時間を取られたので、車体はキャンプの日程開始前にあらかじめ完成させておくことを個人的にはオススメします。
8/8 (1日目)
この日は、開講式・全員必修の共通講義・参加者有志によるLT大会・グループワーク初回が行われました。 私はLTを見ながら車体を組み立てていました。
グループワーク
「グループワーク」というのは、まず受講生全員をランダムに4人1組のグループへ分けた上で(メンターとして各グループにチューター1名が付きます)、グループごとに『セキュリティ・キャンプ修了後に参加者が取り組むこと』を決定し、修了後にそれを実践するというものです。 このシステムの趣旨は『キャンプ修了後に参加者がやりたい活動を「見つける・実行する・継続する」こと』を達成すること、らしいです。 グループワークについては下記の講義概要に詳しいです。
グループワーク初回では、まずお互いに自己紹介をした上で「グループの名前」を話し合って決定します。 弊グループでは私が「一意な名前を付けたい」「少しぶっ飛んだ名前の方が面白そう」という観点から「各メンバーが好きな食べ物を1つ挙げ、それを繋げて1つの名前にする」という提案をしたところ、それが採用され、弊グループは「ハンバーグ抹茶ラーメンジェノベーゼ」という名前になりました。 この前参加した ISUCON 12 の予選で「チーム名」という概念のカルチャーショックを受け、これくらいユニークな名前じゃないと逆につまらないなあという感性が自分の中で構築されつつあります。 575はいい文明ですね。
弊グループの活動内容としては、議論の末「『RISC-VとChiselで学ぶ はじめてのCPU自作』の輪読会をする」ことに決定しました。
https://www.amazon.co.jp/dp/4297123053/www.amazon.co.jp
他のグループを見ていると「CTFコンテストに参加する」ことを掲げているところが結構多かった(例年に比べても特に多かったらしい)ようです。 弊グループでは
- CTFをぜひともやりたいという人が特にいなかった
- チューターさんから「CTFは全員のモチベーションが強く一致していない限り途中で挫折しやすいので、あまりオススメはしない」というアドバイスがあった
ことから、CTFは活動内容の候補から外しました。
8/9 (2日目)
開発コース1日目です。
- 講師・チューター・受講生の顔合わせと自己紹介タイムから開始。私が「関数電卓からプログラミングに入った」と話したところ、講師のpuhitakuさんから瞬時にものすごく的確な返答がやってきて愉快な気分になる。
セキュキャンで最も印象に残ったこと:
— ゆみや (@stepney141) 2022年8月22日
「グラフ関数電卓からプログラミングに入りました」とpuhitaku氏に話したら、「HPですか? TIですか?」と即答されたこと
講義。本ゼミの趣旨と全体的な工程の説明、電気回路・マイコン開発についての座学。
開発。本日の最低限の目標は「パソコン+Arduinoからモーターを制御する」ところまで辿り着くこと。講義資料と各種ネット記事を見ながら、もくもく会状態で各自作業を開始。
電気回路との戦い・序
まず Arduino Nano Every の動作確認のため、パソコンと接続してLチカをしてみる。シリアルポート周りのエラーで一瞬つまづくが自己解決。その後、モーターにコンデンサをハンダ付けするところでかなり手こずる(ざっくり2時間はかかった記憶)。細い導線の被覆をうまく剥がすのにも苦労した。
Arduinoからモータードライバを制御するための回路をブレッドボードに実装し始める。この回路には「ツッコミどころ」があるので見つけたら改善策を吟味してみよう、とのこと。しかしパッと見した限りでは見当がつかないし、無知な自分がいくら考えたところで時間をただ浪費するだけになりそう。なのでまずはお手本を実装することに集中する。回路図とArduinoのピン配置図とモータードライバキットのデータシートを見ながら、手探り状態でジャンプワイヤーを挿していく。ここに挿すんで本当に合ってんだろうな?と図を確認してはミスを見つけて挿し直す、という「三歩進んで二歩下がる」を地で行くような作業を繰り返す。
15:30、各自の進捗を報告。他の受講生のお2人と比べて自分が遅れ気味であることに気づき、焦り始める。お2人がナチュラルに私物のオシロスコープを活用していてビビった。
電気回路との戦い・破
16:00頃、とりあえずお手本の回路図がブレッドボード上に再現されたような気がする。まず、Arduino言語のレファレンスを見ながら、パソコンとArduinoの間でシリアル通信ができることを確認する。次にお手本やネット資料を見ながら、Arduinoからモーターを制御するためのコードを書く。そして、Arduinoにコードを書き込んでパソコンからモータードライバを制御する。
あれ、パソコンから命令を送ってもモーターが動かないな。Arduino単体のLチカは動くから、Arduinoが壊れて動かなくなったというわけではなさそう。ブレッドボードの接触不良とかかしら? 回路図を見ながらジャンパワイヤを全て取り外して別のワイヤで挿し直し、Arduinoを書き込み直して再接続する。しかし状況は変わらず。
17:30〜18:30、夕食時間。と言っても時間帯が早すぎて喉を通らないし、さっきまでぶっ続けで作業してた人間にとっては、いきなり夕食を準備・消費して片付けまで済ませるには時間が足りなさすぎる。仕方ないので軽食で済ませる。IPAさん、この点どうにかならなかったんでしょうか。
作業再開。動かないのは回路をどこかで挿し間違えているからではないかと考え、全てのジャンパワイヤと基板を外してブレッドボードに挿し直す作業を再度行う。しかしモーターは動かない。キエーッ。
テスターを起動してみるが、電子回路やマイコンにおける不具合原因の切り分け方が分からず、どの辺の部分からチェックしていけば良いのか見当がつかない。とりあえずモーターと導線を外して単3乾電池に繋げると、勢い良くモーターが回り出した。つまりモーター部分の問題ではなく、Arduinoまたは回路部分の問題であることは分かった。
20:20、本日やったことの報告。他の受講生のお2人が最低限の目標を遥かに超え、本来明日やるはずの範囲まで辿り着いていたことを知り、一人で内心ビビり散らす。回路が動かないことについて手元をカメラで映しつつ皆さんに相談し、間違った箇所に挿さっているジャンパワイヤがまだ残っていたこと、モータードライバキットの基板にピンヘッダとターミナルブロックをハンダ付けしなくてはならなかったことを知る。
入浴・食事を済ませた後、今日の作業でかなり疲労困憊したのでしばらく休む。今日はとりあえず回路が動くようになるまで作業を続けることにする。
23:20過ぎ、作業再開。ピンヘッダとターミナルブロックのハンダ付けを始める。細かい箇所にうまくハンダごてを当てるのにかなり神経をすり減らす。フラックスを塗ってもハンダが全然基板に乗ってくれない、なぜだ。上手なハンダ付けの仕方をGoogle検索しつつ色々とやってみるが、特に状況は改善しない。俺はこんなに不器用だったっけ、厳しいなぁ、と思いつつハンダの煙を吸い込み続ける。
午前2時台、やっとハンダ付けが完了した。意気揚々とArduinoとパソコンを接続するが、Arduinoのオレンジ色のパイロットランプが点灯するばかりでモーターは動かない。なぜだ。モータードライバの基板やモーターのハンダ付けの接触不良を疑い、ハンダを吸い取って付け直す。が、動く気配はない。ハンダ付けした部分をテスターで調べてみても、短絡している様子はないし、接着部分も通電している。
結局、5時過ぎになって気力が尽き、今日の最低限の目標が達成できないまま横になる。
8/10 (3日目)
開発コース2日目です。開発コースの日程は一応全部で3日間となっていますが、終日開発できるのは実質的にこの日が最後です。早すぎる。
電気回路との戦い・急
8:00、起床。徹夜や朝寝は自分にとって日常茶飯事だが、3時間睡眠でこれほどすっきりと疲れが取れたことは今までになかった。しかしそれが余計に「早くデバッグを終わらせなくては」という焦りを加速させる。
9:30、作業開始。まずは自分の昨夜の状況を報告し、モーターを動かせない原因が分からない件について相談する。カメラでブレッドボードを映し、皆さんから「回路自体にミスはなさそう」というコメントを頂く。puhitakuさん「Arduino自体が破壊されているという可能性もある」。
チューターさん*2「テスターでArduinoのピンにかかっている電圧を調べてみて下さい」。テスターでArduinoのGNDピンと他のピンにどれだけの電位差があるか、導通していないかを調べる。しかし、データシートと照らし合わせても異常な兆候は見られなかった(=Arduino自体が壊れているということはなさそう)。
チューターさん「次はモータードライバの基板をテスターで調べてみて下さい」。電源を供給しない状態で基板の端子同士が短絡していないかを調べた後、Arduinoから基板にモータードライバのデータシート通りの電圧を入力し、モータードライバからどれだけの電圧が出力されているかを調べる。期待通りの入出力がなされている。あれ?じゃあなんで動かないんだ?
一旦整理をするとこうなる。
もしかして、モータードライバに加わっている電圧が小さすぎたせいでモーターが動かなかったのでは...? ということはPWMのデューティー比が小さすぎてモーターが回らなかったのかな。とりあえずArduinoのコードを全面書き直した方がいいなコレ。
11:00過ぎ、Arduinoのコード内で指定しているPWMのデューティー比を色々と調整しつつ、モータードライバのデータシート通りの電圧を加えてみたところ、回路に繋げられたモーターが勢い良く回転を始めた。ここに至って1日目の最低限の目標をやっとクリア。オシロスコープがあったらこの辺の原因究明もスムーズに出来てたんだろうか。
UARTでPCからArduinoを制御してモーターを動かすやつ、他の人々からだいぶ遅れてやっとできた #seccamp
— ゆみや (@stepney141) 2022年8月10日
ルーターの設定
- 1日目の内容を何とかクリアしたので、急いで2日目の内容に入る。まずルーターを開梱・分解し、講義資料を見ながら基板にどういう部品が付いているのかを確認。ルーターをUSB Ethernetアダプターでパソコンと接続して初期設定を行う。講義資料を見ながらやっていたら20〜30分ほどで完了し、パソコンから無線でルーターに接続できるようになった。
ルーターをマイコンに接続
ルーターに無線接続できるようになったので、本格的にルーターを改造する準備に入る。まずルーターに sshし、シリアル通信を使うためにパッケージマネージャで minicom を導入する。minicom を ssh 越しに起動しようとしたが、普段使っている urxvt というターミナルエミュレータでは minicom を起動できず、代わりに xterm を開く。
xterm のデフォルトのフォントやスタイルが見づらかったたため、
xterm -fa "xft:TerminessTTFNerdFontMono-20, xft:IPAGothic" -fg PapayaWhip -bg "rgb:00/00/80"とオプションを付ける。xterm から ssh して再度起動を試みると、今度は問題なく minicom を開くことができた。ルーターの USB Type-A ポートにArduinoを接続し、ルーター上の minicom から Arduino に命令を送る。すると期待通りにモーターが回ってくれたので、次の工程に進む。ルーターの設定完了からここまでで約15分。
REST APIサーバ・フロントエンド画面の開発
次は、curl を叩きながら HTTP 通信と REST API について学ぶ。この辺は割と馴染みがあるので特に苦労はしなかったが、考えてみると自分にはネットワーク周りの知識がだいぶ欠けているんだよな。自分が知っているのはアプリケーション層の話だけで、それより下の層のことは何も知らないなあということに改めて気付く。
HTTPの話を踏まえて、ルーター上で動かすREST APIサーバを作る。講義資料の通りに MicroPython と各種ライブラリをルーター上に導入し、ファイアウォールを設定する。講義資料では vim も導入することでルーター上で全ての開発を行うようになっていたが、自分は VSCode でコードを書き、更新する度に逐一 scp でルータにファイルを送信するようにした。個人的にはこの方が楽に感じる。
サーバのお手本コードは予め提示されていたので、これを参考にしつつ自前で実装する。REST APIを叩くのは日常的にやってるけど、Python でバックエンドのREST APIサーバを組むのは地味にこれが初めてなんだよな。MicroPython を使う関係上、お手本も Python で書かれていたが、個人的にはできれば書き慣れている Node.js を使いたいところ。しかしユーザーが自由に使えるストレージ領域はかなり小さいから、node_modules みたいな巨大な代物を入れられる余地はなさそうである。とりあえずは講義資料の通りに Python での実装を進める。サーバが形になってきた段階で curl から REST API を叩き、期待通りに HTTP 通信が行えていることを確認。
ブラウザからREST APIを叩くための操作画面を作る。お手本の HTML ファイルには Bootstrap 5 が使われていた。サーバが形になってきて、もう少しでフロントエンドからAPIを叩けるようになりそうかな?という段階になった辺りで本日の日程は終了。
ハードウェア部分は完全未経験だったため死ぬほど手こずり、朝5時まで動かない原因を探すなどして丸1日以上費やしてしまったけど、REST APIサーバとフロントの部分は日付が変わるまでには終わりそう #seccamp
— ゆみや (@stepney141) 2022年8月10日
22:30頃、「フロントエンドからREST APIを叩くと、それに応じてルーターが動く」という挙動ができるようになる。とりあえずX3ゼミ全体の最低限の目標にはこれで行き着いたことになる。
お手本のHTMLファイルには、前後左右への方向転換ボタン・停止ボタンこそ備えられていたが、速度を調整する機能はなく全速力で走行するようになっていた。これは不便だし、自分なりの工夫も付け加えておきたかったので、
<input type="range">で速度を調整できるようにする。Bootstrap を使うのは高校の文化祭のサイトを作らされた時以来である。懐かしいなーと思いつつ公式ドキュメントを開き、HTMLファイルを編集する。振り返ってみると、REST APIは元々の実装だと「前・後・左・右・停止」の命令しか受け取らないようになっているし、Arduinoも速度を調整可能なような実装にはなっていない。つまり、「速度を変えられるようにする」という一つの仕様変更が、全てのレイヤーに連動して影響を与えるということになる。結局
<input type="range">でモーターのデューティー比を直接指定し、それがREST APIサーバを介してArduinoに直接送られるように全体を書き換えることにした。昨日の徹夜でそこそこ体力を消耗していたため、今日は早めに(当社比)2時頃に寝る。
8/11 (4日目)
この日は開発コース内での成果発表会がありました。最終日に各コースの代表者が1名ずつ「自分のコースでやったこと、自分が工夫したこと、自分が得た学び」などを発表する時間が設けられていますが、今日の成果発表会はその準備あるいは予選のようなもので、参加者全員が自分で作ったスライドで発表を行います。
8:30、作業開始。この日は座学はなし。午後は成果発表会のスライド制作をしなくてはならないので、作業が可能なのは事実上この午前中いっぱいに限られる。フロントエンド・REST APIサーバ・Arduinoのコードの書き換えと調整に時間を費やす。
13:30頃、成果発表会のスライドを作り始める。ゼミ発表のためにスライドを Marp で作る習慣が元からあったので、この辺は特に苦労せずいつも通りにスライドを作る。デザインはゼミ発表のためにいつも使っているスライドテンプレートをそのまま流用した。Marp はまあまあ綺麗な見た目のスライドが Markdown でパッと作れて便利なのでオススメです。
16:30〜17:30、成果発表会。電気回路周りの話に関しては自分よりも他の受講生のお2人の方が明らかに深く理解されていると思ったので、自分は「このゼミからどういうことを学んだのか」に主眼を置いた発表をした。X3コースの受講生全員が Marpを使ってスライドを作っていたことが判明し、「Marpいいですよね」という話で盛り上がった。
他の開発コースの発表を聞くと、どのコースも面白そうなことをやっているなあと感じる。最後まで応募を迷っていたCコンパイラゼミ・CPU自作ゼミの発表が聞けたのは良かった。また、応募は特に検討していなかったが、暗号のままで計算しようゼミ・無線通信ハッキングゼミの発表が個人的に特に面白かった。「理論的な話に興味を惹かれる」という自分の興味の傾向によるものだろう。
夜の日程として、再びのLT大会とグループワークがありました。LT大会は3つのトラックに分かれ、各時間に開かれる3つの発表の中から好きなものを選んで視聴するという形式でしたが、どれも面白そうな内容でどれを見るかかなり迷いました。 日程終了後、0時が期限の期末レポートを一気に仕上げて提出するなどしていました。
2時過ぎ、講義資料の最後に「発展的内容」として紹介されていたOpenWrtのビルドをやってみる。
色々いじっていると、理論上は OpenWrt で Node.js などを動かせるっぽい、ということに気付く。REST APIサーバはNode.jsで書きたかったけど、組み込み環境だし厳しそう。
OpenWrt をビルドしようとしてたら make menuconfig の Languages に "Erlang" とか "Node.js" といった文字列が躍っているのを見つけ、おもしれーヤツという気持ちに #seccamp
— ゆみや (@stepney141) 2022年8月11日
- するとpuhitakuさんからDiscordで「ストレージの容量がカツカツな場合、USB フラッシュメモリのような外部ストレージを rootfs にできる extroot というテクニックを使えば広大な領域が手に入ります」「DRAM は余裕なはずだから、あとは rootfs の容量さえ extroot とかで手に入れれば Node.js, gcc, CPython も夢じゃないですね 」というアドバイスを頂いた。
- extroot ってこれかぁ。楽しそうだな。しかし今はとりあえず講義資料の最後まで行き着くことを優先させたい。extroot は後でやることにして、今は講義資料で書かれていた設定でビルドしてみることにした。
OpenWrt の make -j4 を開始 (2時46分, @ Intel i7-8550U, 4コア8スレッド) #seccamp
— ゆみや (@stepney141) 2022年8月11日
巨大なコードベースのビルドを今までやったことないから、コア数とか気にするの初めてだな
— ゆみや (@stepney141) 2022年8月11日
ふとファンの音がしなくなっていることに気づき、画面を見たらmakeが正常終了していた
— ゆみや (@stepney141) 2022年8月11日
- ビルド完了を確認した後、4時過ぎに就寝。
8/12 (5日目)
午前8時過ぎに起床後、グループワーク・成果発表会・閉講式がありました。 ビルドしたOpenWrtのバイナリをルーターに書き込み、しばらく遊びました。
完走した感想
獲得した学び①:様々なレイヤを知ることの大事さ
X3ゼミでは「様々な技術を自分で触り、それを互いに組み合わせることで一つの物を作る」という体験をします。 これを経て気付かされたのは「現代のプロダクトは、抽象的な高レイヤ層から工学的な低レイヤ層まで、幅広い技術が膨大な単位で集まった上で、それらが互いに組み合わさることによって動いている」ということでした。 人はともすれば「自分の専門分野」「自分が今知っている技術」だけに閉じこもってしまいがちな生き物ですが、それでは様々な技術を投入されて精巧に作り上げられている現代のプロダクトについて学んだり、遊んだり、それこそ攻撃に備えたりするためには支障が生じます。
また先程触れたように、現代のプロダクトは様々なレイヤ層の幅広い技術を組み合わせて作られている以上、自分で何か新規性のあるプロダクトを作るには、それを構成する要素となる各レイヤについて自分自身が手の動かし方を心得ておく必要があります。 これは既存のプロダクトをリバースエンジニアリングしてその上に自分なりの改造を施すにせよ、自分で一から設計してプロダクトを作るにせよ、どちらにしても変わらないことです。 むしろ前者の方が、他者が設計したものをゼロから読み解く必要がある以上、各レイヤに通じておく必要性もより強くなると言えるかもしれません。 私はこのセキュキャン講義を通じて、様々なレイヤのお気持ちを幅広く知ってこそ自分の力で面白いことができるようになるということを学びました。
獲得した学び②:「お気持ち」の大事さ
上の獲得した学び①のところで「お気持ち」という言葉を使いましたが、そもそも「各レイヤの技術を学ぶ」とは一体どういうことなのでしょうか。 自分が今回苦戦した電気回路を例に考えてみます。
電気回路を組む上では「上手なハンダ付けの仕方」のような専門的技能も非常に重要ですが、それ以上に大事と感じたのは「なぜコンデンサをここに入れるのか」「回路が動かない時、どういう方向に思考を働かせて、どういう風に原因を切り分けたら良いのか」といった『その分野の思考法に関する知識』です。 頭の使い方・手探りの仕方・これの何が嬉しいのか...といった「お気持ち」を会得することが、新しい技術を学ぶ上で重要であると感じました。 考えてみれば至極当然のことなのですが、やったことのない分野に改めて入門してみるということをしばらくしていないと、「お気持ち」の重要性を忘れてしまうようです。
でもまあ苦戦した最も大きな原因は、「上手なハンダ付けの仕方」のような直接的な知識があやふやだったことよりも、「回路が動かない時の原因の切り分け方や頭の使い方」が欠落してたことだと思う
— ゆみや (@stepney141) 2022年8月10日
電子工作の中で自分が今回詰まったポイントとして、例えば「基板にターミナルブロックやピンヘッダをハンダ付けする必要があることを知らなかった」という点があります。 しかしこれも「ブレッドボードや基板の端子がどのようにして通電しているのか」をちゃんと調べながら演繹していれば「端子とブレッドボードを接続するために、ピンヘッダやターミナルブロックをハンダ付けする必要がある」ということをすぐに導き出せていたはずです。
私には昔から「触れたことのない分野に弱く、蛇の道程度の細い道を通すだけでも、ゼロ知識からやり始めると時間がかかる」「一度蛇の道を開拓した後はまあまあ習熟が早い」という性質があり、これが今回モロに出てしまったように思います。
その他所感
- 「自分の全ての思考リソースと体力を、何か1つのものを開発することにのみ全振りする」という体験は初めてで、とても楽しかった
- 開発を通じて、未知のレイヤと既知のレイヤを自分の手で接合させていく感覚が面白かった
- 低めのレイヤの歩き方の第一歩を踏んだので、以前からの趣味(関数電卓のプログラミング)における目標(関数電卓のハックとリバースエンジニアリング)に活かしたい
- 組み込みLinuxに興味が湧いた
- 自分が思ってた以上に自分が電気周りのことをなにも知らないことに気づいた
- 電気回路はコンピュータの実装と動作のために切っても切り離せないレイヤなので、電気そのものを専門的にやる必要はないにせよ、もう少し知っておくべきだなと実感
- グループワークのCPU自作本輪読会を通してこの辺の理解を少しずつ深めたい(でもあの本でやるのはエミュレータ実装なんだよな)
- ネットワークについても、自分はアプリケーション層より下の話のことをなにも知らないと実感
- Discordのボイスチャットで何度か話が出ていた llvm も、今はボヤっとしか知らないが既知にしたい
セキュキャンの深夜ボイチャで「グラフ関数電卓の独自プログラミング言語の処理系を自作したい」という目標が発生したので、今後ゆるゆるとやっていきます
— ゆみや (@stepney141) 2022年8月12日
私の履歴書 〜#seccamp 2022グループワーク記事〜
この記事は私の自己紹介です。 なぜ今更になってそのような記事を書くのかというと、先日終了したセキュリティ・キャンプ全国大会2022がきっかけです。
セキュキャンには「グループワーク」というシステムがあります。 これは『セキュリティ・キャンプ修了後に参加者が取り組むこと』をあらかじめ取り決めておき、4名の参加者から成る班活動を通してそれを実践するというものです。 このシステムの趣旨は『キャンプ修了後に参加者がやりたい活動を「見つける・実行する・継続する」こと』を達成すること、らしいです。 グループワークについての詳細は下記の講義概要を参照ください。
さて、我々のグループ「ハンバーグ抹茶ラーメンジェノベーゼ」は、本格的な班活動の第一ステップとして「自己紹介の代わりとなるブログ記事を執筆し、興味関心・得意分野をお互いに知るきっかけにする」ことにしました。 これは、今年のセキュキャンが全面オンラインかつ5日間という短期間での開催だったということから生まれた、「お互いがお互いのことをよく知らないままグループワークを始めなくてはならなくなっている」という問題を解消するためです。 まず最初にこのような自己紹介ブログによる交流を挟むことによって、活動を円滑にやっていこうという狙いがあります。
私の自己紹介は https://stepney141.github.io/ にだいたい全て書いてあるため、まずはそちらをご覧ください。 本記事にはその補足を書き連ねることにします。
私の専攻分野は経済学なのですが、それ以前から趣味で開発に参加していた「Dagaz」というボードゲームエンジンをゼミ研究のテーマに選び、最近は参考としてコンピュータ将棋ソフトに使われている技術を色々と追っています。
それとは別に、小学生の時から「プログラム関数電卓」というガジェットで遊ぶことを趣味としています。 今回のセキュキャンでは「高いレイヤと低いレイヤの密接な繋がり」について学び、低いレイヤ層の歩き方を少しだけ知ったので、そこから更に発展させて関数電卓というガジェットをよりディープに遊び倒すことが出来たらなと思っています。
上で「関数電卓による気象数値予報の試み」という記事を貼りましたが、昔からこういう数値シミュレーションの分野が好きで、以前は気象や天文の数値シミュレーションの分野に入り浸っていたこともありました。 多分「現実の事象をコンピュータ上の計算という形で再現する」という行為に昔から惹かれているのだと思います。
趣味としては、昔から読書が好きです。 「読書メーター」というWebサービス上にアカウントを持っており、これまでに読んだ本・これから読みたい本・積読してる本などの情報をここに集約させています。 興味がある本の対象はだいぶ色々で、かなりの雑食なのですが、もし興味が被っているジャンルがあったら教えてください。
読みたい本が大学図書館に所蔵されているかどうか確認するスクリプトを組んでおり、GitHub Actionsで定期実行しています。 GitHub上で管理しているため、読みたい本の差分がバッチリ管理できるといううれしい副作用もありました。
これは、毎月読んだ本の感想を書こうと思ったはいいものの結局一回きりになってしまった、本の感想記事です。
セキュリティ・キャンプ2022全国大会 (ハードウェア魔改造ゼミ) の応募課題を晒す話
この度、セキュリティ・キャンプ2022全国大会の開発コース「X3 ハードウェア魔改造ゼミ」の選考通過の連絡を頂くことができたので、個人メモを兼ねて、伝統行事になっているらしい応募課題晒しをしておこうと思います。どなたかの参考になれば幸いです。
※回答の内容の正確性について筆者は一切保証しません。
#seccamp の X3(ハードウェア魔改造ゼミ)、通りました
— ゆみや (@stepney141) 2022年6月6日
対戦ありがとうございました&対戦よろしくお願いします
セキュリティ・キャンプとは
経済産業省の外郭団体・IPA(情報処理推進機構)及び一般社団法人セキュリティ・キャンプ協議会が主催している、若年IT人材の発掘・育成事業という名の無償勉強会です。 内容としては、暗号・Web技術・低レイヤ開発・ハードウェア解析などの多様な分野の中から希望するコースを選び、その分野の専門家から指導を受けつつ何かを学んだり実装したりするということをやるらしいです。
参加者は書類選考で決まります。参加希望者は興味のあるコースを最低1つ選んで、そのコースで扱う分野についてあらかじめ与えられている応募課題を提出します。この課題の出来が一定の水準を満たしていると書類選考通過となります。 2019年までは対面での合宿形式で開催されていましたが、2020年以降は新型コロナウイルスの流行を受けてオンライン開催が続いています。 合宿形式のセキュキャンを体験してみたいとも思いますが、多分オンラインにしかないメリットもあるのだろうと思います。
今年の応募に至るまで
個人的備忘録を兼ねて自分語りをします。個人ブログなのでポエムを書くのは許して下さい。
私が初めてセキュキャンのことを知ったのは2017年くらいのことだったらしいです。私がTwitter上で計算機オタクの人々と繋がるようになったのがちょうどその頃だったことを鑑みると、おそらくTLに参加者のツイートが流れてきたのを見て知ったのだと思います。
この頃からセキュキャンには興味を持っていましたが、純粋な実力不足・大学受験・中学時代から患っていた起立性調節障害による学業成績とメンタルの崩壊などにより、応募は叶いませんでした。
大学受かってセキュキャン行きたい
— ゆみや (@stepney141) 2019年4月16日
2020年:全国大会に応募する予定でいましたが、新型コロナウイルスの流行のためオンラインで開催されるとの報を受け「オフラインじゃないならいいかな...」と応募を見送りました。hsjoihsさんがCコンパイラゼミのチューターとして色々とツイートされていたのを自室からTweetDeckで眺めていた記憶があります。
2021年:年が明けても流行が収まる気配がなかったため、同年のオンライン全国大会への応募を決めました。興味のあるコースは複数あったものの、当時Web開発にのめり込んでいたこともあって、プロダクトセキュリティトラック「B1 ちいさなWebブラウザを作ってみよう」を志望。しかし課題の重さに心が半分折れ、固有スキル「精神的プレッシャーによるタスクの後回し: A+」が発動してしまう事態に発展しました。結局、回答提出期限の1週間前になるまでまともに課題をする気が起こらず、ズタボロの内容の回答を提出することになり、あえなく落ちました。まあ「クイズの正答を探すのではなく、自分の頭で思考した内容を記述する」という能力そのものが当時の自分には完全に欠けていたので、まともに準備をしていたとしてもまず落ちていただろうと思いますが...。
セキュキャン2021、普通にダメでした
— ゆみや (@stepney141) 2021年6月10日
通った皆さんおめでとうございます
2022年:昨年の反省を踏まえ、応募の準備をいち早く開始しました。まず、クラス一覧を見ていて惹かれたものを以下の通りピックアップしました。
今年は講師陣によるTwitter上での宣伝の勢いが凄く、倍率も一昨年・昨年に比べて相当上がることが予想されたため(実際、一昨年・昨年と違って今年は応募締切が延長されませんでした)、かなり力を入れて回答を書かないと通れなさそうだなという直感がありました。そのため当初は、単願ではなく「選考通過の可能性を増やすため、興味のある複数のコースに数を撃つ」という戦略を取ろうと思っていました。 可能であればピックアップしたもの全てに応募をしたかったのですが、開発コースと専門コースの併願は不可能であったためBトラックへの応募は見送り、さらに併願数の上限は3個であったため、最も興味があったX3・L3・Y4に応募しました。
しかし、いざ回答を書き始めてみると(当然ですが)課題がどれも重かったことにまたもや悩まされました。回答期限まであと2週間を切ろうかという頃に後回しスキルの発動の兆候を自覚したため、ここで方針を大きく変え、「精神的負荷を減らして1つの課題に集中するため、併願をやめる」という戦略を取ることにしました。単願するコースとして、以下の理由からX3を選びました(特に2.と3.が大きかったです)。
- 回答が書きやすそう
- セキュキャン以外で同じことが出来る機会がなさそう
- X3講師の puhitakuさん (末田さん) が手掛けていらした電子辞書ハックに以前から興味があった
※私は以前から関数電卓のハック界隈におり、puhitakuさんの電子辞書ハックのプロジェクトをTwitter上でたまたま拝見した時からずっと氏の活動が気になっていました。
結果的に考えると、この方針転換がより良い回答を作るために効果的だったように思います(回答提出期限当日に食事会があり、中華料理店で紹興酒を飲んで適度に筆が乗った状態で回答を仕上げることになったのですが、もしかするとこれが効いた可能性もあります)。
授業をフル単しているので平日はあまり回答を書く時間を取れず、主に放課後と休日に図書館に籠もって一気に回答を仕上げる形を取りました。
ともあれ、貴重な機会を無駄にしないようこれから精進していきます。
回答の方針
回答作成を通じてかなり有意義な思考訓練ができた気がするので、備忘録として回答を書く上で注意したことを書いておきます。どれもかなり自明なことなのでわざわざ書くのも恥ずかしい気がしますが、個人ブログなので当たり前のことを書くのも許して下さい。
- 以前から「セキュキャンの課題は加点式なので、少しでも多く思考の過程を書くべき」「正答があるクイズに答える感覚でやらずに、深堀りして丁寧に調査・思考するようにすべき」と聞いていたので、これを基本方針として回答をまとめました。とにかく全ての設問に回答することを考えました。
- 思考の過程を極力丁寧に書くようにしました。問われていることを調べていくうちに「なんだこれ? 初めて聞いたな、よう分からんな」と思ったワードがあれば、それが回答を直接求められているわけではない概念であっても、そのワードについて得た理解を併記するようにしました。
- セキュキャンの応募課題は「このコースではこういう感じの話をやるから予習してきてね」という趣旨だと聞いたことがあったので、「設問に回答する」というよりも「自分がその分野について勉強したことをガイドラインに沿ってまとめる」というようにすることを意識しました。
- 課題で問われた内容が今までやったことのない完全初見の分野ばかりだったため、これを強く意識しないと自分にはそもそも何も書けなかったという事情もありました。
- 学科のゼミで実感したことですが、自分でもよく分かっていないことを他人にちゃんと説明することはできないので、可能な限り多数の参考文献を参照して勉強するようにしました。
セキュキャン応募課題を仕上げようとしている最中なんだけど、この営み何かに似ていると思ったらゼミ発表だ
— ゆみや (@stepney141) 2022年5月23日
設問
設問の内容をここに引用しておきます(原文:https://www.ipa.go.jp/files/000097409.txt)。
(1)以下の技術用語について解説してください。またどのようなところで使われているかも述べてください。わからない場合は調べて、自分なりに解釈した結果を述べてください。
「オームの法則」「UART」「SPI(Serial Peripheral Interface)」(2)マイコンのファームウェアをデバッグするためには、どういう方法がありますか?
(3)電気には直流と交流があります。同じ電圧のとき、どちらが感電したときに危険だと思いますか?その理由と一緒に説明して下さい。また感電はどんな工夫をすれば防げるでしょうか、思いつく限り多く挙げてください。
(4)このデータシートから、以下の情報を読み取ってください。
データシートURL:
https://datasheets.raspberrypi.com/rp2040/rp2040-datasheet.pdf
rp2040-product-brief.pdf (raspberrypi.com)・GPIOに5.0Vを入力しようと思います。この機器は正常に動作しますか?
・この機器でSPI通信は使用できますか?
・IOVDDとDVDDの違いを説明してください
・SWDポートを使うと何ができますか?
・GPIO 1ポートから標準で何mA出力できますか?またGPIO合計で最大何mAまでの電流を出力できますか?(ただしQSPIポートで使用する電流は考慮しないものとします)(5)以下の質問に答えてください。
・電波を発射する装置を日本国内で合法的に使用するには、「電波法で定められた基準に適合しているという証明」が得られた無線機が必要です。この証明の名前はなんですか?
・市販されている無線ルーターの多くには、機能を完全に置き換えられる純正ではないファームウェアが存在します。非純正のファームウェアがインストールされた状態でWi-Fiを有効化すると、上記の証明が無効になり違法となる可能性があります。何を原因としてその可能性が生じるのか考察してください(簡潔な記述を望みます・400文字以内)。
第1問
オームの法則
「回路に加わる電圧Vは、回路を流れる電流Iに比例する」という関係のことで、Rを回路中の抵抗として「V=RI」という式で表される。これを「I=V/R」の形に変形すると、「電流の流れにくさは電流の大きさに反比例する」という関係が読み取れる。つまり、回路中の電気抵抗が小さければ、回路に過大な電流が流れることがオームの法則から導かれる。大電流は回路の発熱・発火の原因になる上、回路に組み込むLEDなどの電子部品は正常に動作する電流の定格が定められているので、その値を超えた電流を流すと回路が破損する恐れがある。このため、回路には必ず適切な大きさの抵抗を組み込み、電流の大きさを制限する。この時に回路に組み込む抵抗の「適切な大きさ」そのものも、オームの法則を使って計算される。オームの法則は電子回路設計におけるもっとも基本的な法則である。
参考文献:
- 『学びやすいアナログ電子回路(第2版)』二宮保・小浜輝彦, 森北出版, 2021
- 『Make: Elecrtonics 第2版』Charles Platt, O'Reilly Japan, 2020
UART
Universal Asynchronous Receiver Transmitterの略で、調歩同期方式のシリアル通信とパラレル通信の相互変換を行う集積回路のこと。情報を構成するビットを送受信する時、単一の信号線上に1ビットずつ逐次的に送受信する方式がシリアル通信で、複数の信号線上に複数のビットを並列して送受信する方式がパラレル通信である。調歩同期方式とは、送信する機器・受信する機器で共通のクロック信号を共有せず、送信側が「これからデータを送る」「これでデータを送り終えた」という信号を実際のデータの間に送信し、送信側・受信側同士で歩調を合わせながら通信を行う方式のことである。
UARTの用途としてはCPUと外部周辺機器を繋ぐためのインターフェースとして使われることが多く、かつてはパソコンとモデム等の周辺機器を接続するためにも広く使われていた。しかし、通信速度が比較的遅いことから、センサーのような高速なデータの送受信が求められる機器には向かない上に、接続されている周辺機器の情報を取得する方法がないため、現在はパソコンの外部接続用途でもあまり使われなくなっている。一方で、仕組みがシンプルであるため開発工数が少なく済むという利点があり、現在は組み込みシステム・マイクロコントローラで活用されることが多い。
最も単純なUARTの入出力線は、CPU等に接続するためのパラレルバスと、他のUARTに接続するためのTX(送信)・RX(受信)の2本の信号線から成る。TX(Transmit Data)の信号は出力信号で、他のUARTに、調歩同期方式のシリアル通信でデータを送信する。RX(Receive Data)の信号は入力信号で、他のUARTから、調歩同期方式のシリアル通信でデータを受信する。CPUからUARTにデータが送信されると、パラレルバスから8~16bitの幅で複数の信号がUARTに送られてくる。するとUARTはこの複数のデータ信号を1本のデータ信号に変換し、シリアル信号として送信(TX)する。逆にUARTがシリアル信号を受信(RX)すると、複数のデータ信号になるまでデータを溜め、パラレル形式にデータを変換してパラレルバスでCPUに信号を送信する。2つのUART間で通信を行う場合、一方のUARTのTXをもう一方のUARTのRXに、一方のUARTのRXをもう一方のUARTのTXに、それぞれ接続する。この時、両方のUARTのボーレート(情報を転送する速度のこと)の値を同一に揃えておく必要がある。なぜなら、送信側・受信側は互いにクロック信号を共有しないので、お互いが同一の速度で送受信しなければ同じタイミングで通信を行えないためである。
参考文献:
- 『マイクロコンピュータ入門 高性能な8ビットPICマイコンのC言語によるプログラミング』モニシャガ=ワシリー・森元逞・橋本浩二, 共立出版, 2022
- 『組込みエンジニアの教科書』渡辺登・牧野進二, C&R研究所, 2019
- https://wa3.i-3-i.info/word12982.html
- https://www.analog.com/jp/analog-dialogue/articles/uart-a-hardware-communication-protocol.html
- https://www.rohde-schwarz.com/jp/products/test-and-measurement/oscilloscopes/educational-content/understanding-uart_254524.html
- https://synapse.kyoto/glossary/uart/page001.html
- https://xtech.nikkei.com/it/pc/article/NPC/20070517/271422/
- https://emb.macnica.co.jp/articles/8191/
SPI(Serial Peripheral Interface)
同期的なシリアル通信インターフェースの一つ。SPIで通信するデバイスはマスタ(主)とスレーブ(従)に分かれて通信を行い、クロック信号によってマスタとスレーブが同期してデータ通信を行う。クロック信号を生成する方がマスタと呼ばれ、1つのマスタデバイスに複数個のスレーブデバイスを接続することが出来る。ただし、マスタは同時に1つのスレーブとしか通信できない。通信の制御はマスタが行い、マスタがスレーブに送信する場合でも、スレーブがマスタに送信する場合でも、常に通信はマスタが開始する。一般的な4線式のSPIでは、SCLK(Serial CLocK)・MISO(Master In Slave Out)・MOSI(Master Out Slave In)・SS(Slave Select)という4本の信号線で構成されている。マスタで生成されたクロック信号はSCLKを通じてスレーブに送信される。MOSIとMISOはデータを送受信するための信号線であり、MOSIは、マスタからスレーブに対するデータの送信に、MISOはスレーブからマスタにデータを送信するために用いられる。SSはマスタが通信するスレーブを選択するために用いられる。用途としては、主にマイコンと周辺デバイス、またはCPU同士の接続が挙げられる。特に、高速でなおかつ複数のデバイスと通信できるという特徴から、高速な通信が必要なAD/DAコンバータやSDカードのようなストレージデバイスとの接続に用いられることが多い。
参考文献:
- 『マイクロコンピュータ入門 高性能な8ビットPICマイコンのC言語によるプログラミング』モニシャガ=ワシリー・森元逞・橋本浩二, 共立出版, 2022
- 『組込みエンジニアの教科書』渡辺登・牧野進二, C&R研究所, 2019
- 『電子工作ハンドブック』I/O編集部, 工学社, 2014
- 『Raspberry PiによるIoTシステム開発実習』永田武, 森北出版, 2020
- https://synapse.kyoto/glossary/spi/page001.html
- https://www.diatrend.com/glossary/knowledge_communication.htm
- https://emb.macnica.co.jp/articles/8191/
- https://www.analog.com/jp/analog-dialogue/articles/introduction-to-spi-interface.html
- https://learn.sparkfun.com/tutorials/serial-peripheral-interface-spi/all
- https://manual.atmark-techno.com/armadillo-guide-std/armadillo-guide-std-hardware-expansion_ja-1.0.0/ch06.html
所感
これは「このコースではこういう用語が絡む分野をやるので、予習も兼ねて意味を調べてこい」という趣旨の設問だと解釈しました。オームの法則は馴染みがありましたが、SPIについてはおぼろげに聞いたことしかなく、UARTに至っては完全に初めて聞いた言葉でした。とりあえずGoogle検索したところマイコン絡みの言葉らしいことが分かったので、Web上の様々な資料を閲覧するのはもちろん、図書館で電子工作・組み込み開発・マイコンの本を漁って回答をまとめました。
第2問
まず、ファームウェアという概念と、マイコンのファームウェアのデバッグの特殊性について確認する。 特に組み込みシステムの世界において、CPUで動作するプログラムは、一般的な用語である「ソフトウェア」とは区別して「ファームウェア」と呼ばれる。パソコンのような汎用システムにおいては、アプリケーションプログラムは外部ストレージなどからRAMに読み込まれる。これは、プログラムにバグがあったり仕様が変更されたりした際、読み込むデータを変更すればシステムの機能を変更することができるという仕組みで、このような柔軟な対応が可能なアプリケーションが「ソフトウェア」と呼ばれる。これに対し、マイコンなどを用いた組み込みシステムにおいては、バグによる製品の不具合が起きた時にユーザーの手元の機器のアプリケーションを書き換えるのは膨大なコストとなる。このことから、マイコンなどの組み込み環境で動作するプログラムは、一度書き込むと変更が効きにくい「固いソフトウェア」、つまり「ファームウェア」と呼ばれる。特に商用製品のファームウェア開発の場面では「バグのない完成されたシステム」が要求されるため、徹底したデバッグが重要とされる。
マイコンのファームウェアの開発では、汎用のコンピュータシステムのように同じハードウェア上でプログラムの開発・デバッグを行うことが難しい。つまり、開発環境と実行環境が異なるということになるが、このような開発形態をクロス開発と呼ぶ。 クロス開発におけるデバッグでは、ホスト環境(開発を行うパソコン側)で動くデバッグツールから、ターゲットシステム(実際に動作するマイコン側)にプログラムを送り込み、ターゲット上での実行状況をホストから指示・監視する。このようなデバッグの仕方をリモートデバッグと言う。リモートデバッグを行うためにはホストとターゲットの間の通信手段が必要であり、イーサネット・シリアル通信・パラレル通信などのインターフェースが用いられる。なお、実行環境によってはターゲット側にこのような通信手段がない場合や、あったとしても本来の用途のために既に使われている場合など、通信手段をデバッグに使えない場合があり、この場合は自前の通信手段を持つデバッグツールや、プロセッサのデバッグ機能を利用できるデバッグツールを利用する必要がある。
具体的なデバッグ手段の例として、以下が挙げられる。
- 専用のデバッグ手法・通信手段を用いず、汎用的な手段でプログラムの動作状況を外部に出力させる。例えば「動作状況に応じてLEDランプを点滅させる」「printfなどでログを生成させ、UART・SPIなどの通信インターフェースを介してログ文字列を出力させる」といったものが考えられる。先述の通り、ターゲット側にこのような出力手段がない場合や、あってもデバッグ用にそのリソースを回せる余裕がない場合などには使えない方法である。
- オシロスコープやロジックアナライザと言った機器を用いて信号の波形・電圧などの変化を計測し、プログラムへの入力や制御した結果の出力を確認する。
- 開発環境上でソースコードの静的解析を行い、ターゲット側で実行するより前の段階でプログラムの誤りの有無を検証する。
- デバッグモニタというプログラムを利用する。これはターゲット側に常駐させて動かす小さなプログラムで、シリアル通信などの手段でホスト側と通信し、ホスト側から受け取ったコマンドに従って、ターゲット側の状態を取得・変更してデバッグを行う仕組みである。
- ICE(In-Circuit Emulator)と呼ばれる、システムの状態を取得・変更するための機器をターゲット側に設置する。ICEによるデバッグには主に次の2種類がある。
- フルICE:ICEと呼ばれる、ターゲット側のCPUをエミュレーションする装置を用いる。ICE機器をホスト側とターゲット側の間に接続し、ICE機器をターゲット側のCPUの代わりとしてターゲットを動作させることによってデバッグを行う。ICEをプロセッサの種類ごとに開発しなくてはならないためコストが高くなるなどの欠点がある。
- ROM ICE:フルICEにおいて、ターゲット側のCPUの動作を真似るのではなく「メモリの動作を真似て、メモリアクセス情報の取得・変更を行う」機器を利用するデバッグ方式。
- JTAG ICE:JTAG ICEと呼ばれる機器をホスト側とターゲット側の間に接続し、ターゲット側のCPUが持っているオンチップデバッガと呼ばれるデバッグ機能を、JTAG ICE機器を介する形でホスト側から利用する(この時、ターゲット側の接続にはJTAGというインターフェースを利用する)。原理上、オンチップデバッガを搭載していないプロセッサではこの方法は使えない。
参考文献:
- 『よくわかる組み込みシステムのできるまで』長嶋洋一, 日刊工業新聞社, 2005
- 『組込みシステム概論』戸川望, CQ出版, 2008
- 『わかりやすい組込みシステム構築技法 ソフトウェア編』永井正武・澤田勉, 共立出版, 2006
- 『組込みエンジニアの教科書』渡辺登・牧野進二, C&R研究所, 2019
- https://www.cqpub.co.jp/interface/sample/200511/if0511_chap1.pdf
- https://www.osaphex.com/2018/11/23/%E3%83%9E%E3%82%A4%E3%82%B3%E3%83%B3%E3%81%B8%E3%81%AE%E3%83%97%E3%83%AD%E3%82%B0%E3%83%A9%E3%83%A0%E3%81%AE%E6%9B%B8%E3%81%8D%E8%BE%BC%E3%81%BF%E3%81%AE%E4%BB%95%E7%B5%84%E3%81%BF%EF%BC%88jtag-swd/
- https://monoist.itmedia.co.jp/mn/articles/0703/26/news101.html
- https://www.fsi-embedded.jp/kumico/column/3366/
- https://edn.itmedia.co.jp/edn/articles/0703/01/news133.html
- https://qiita.com/7of9/items/ecdac553a7d325f11870
所感
これも「こういうことをやるから予習してこい」という趣旨のようです。回答に一番苦労した設問でした。
まず「ファームウェア」という語彙はもちろん知っていたものの、冷静に考えると一般的なOSやアプリケーションと何が違うのかまるで分からない。なんとなくレイヤー低めな感じの概念だという知識はあったので、図書館で組み込み系の本を漁り、その中から「ファームウェアとは何か」「ファームウェアのデバッグは高いレイヤーでのデバッグと何が違うのか」に関連しそうな話を集中的に探してまとめ、回答の文章をどう構成すべきかという筋道を立てました。具体的なデバッグ手法を調べたのは一番最後の段階です。
第3問
直流と交流のどちらが危険か:
- まず感電した際に人体への悪影響が出る理由として「電流が脳のシナプスの電気信号を乱すから」「人体は電気抵抗を持っているので、電流が流れる際にジュール熱が発生し、それが原因で内臓や細胞組織が火傷・焼損するから」「心臓に電流が流れると、心筋の規則的な収縮のリズムが崩れ、血液が適切な量・適切な周期で全身に送られなくなるから(不整脈)」といったものが考えられる。
- 次に、直流と交流の違いを考える。直流は一定の電圧で一定の電流が一定の向きに流れる。それに対して、交流の場合は電流の流れる方向と電圧が一定の周期で変化する。このことから、交流電流は直流電流と比較して人体のより広い範囲に電流が拡散して流れると考えられる。
- ここで1.と2.で考えたことを総合する。直流電流は一定の方向に流れるので、感電しても必ずしも心臓に直撃するとは限らないし、電流が流れる範囲が限られるため火傷する範囲もそこまで広くはないはずである。それに対して、交流電流は流れる方向が絶えず入れ替わるため、直流よりも人体の中のより広い範囲を流れると考えられる。すると、交流の方が火傷する範囲も広く、心臓を電流が通過するリスクも高いはずである。
- 以上の推論から、直流よりも交流の方が感電した際に危険であると考えられる。
感電しないための工夫:
- 「感電すると人体に何が起こりうるか」を把握する。感電するとどのような怪我を負ったりどのような死に方をする可能性があるのかを知っていれば、自分から積極的に感電をしようという動機は薄れ、感電するリスクを回避するような行動をするはずである。
- 高電位の場所を濡れた手・濡れた身体で触らない。濡れていると人体の抵抗は小さくなり、オームの法則より、同じ電位でも抵抗が小さいほど流れる電流はより大きくなる。
- 確実にアース(接地)を行う。アースをすることで、漏電しても電流が人体を通過することを防ぐ。この時、アース線が導電体に接続されないよう注意する。
- 電気を扱う際は、ゴムなどの絶縁体でできた手袋をはめ、電流が直接体に流れないよう肌の露出を抑える。
- 漏電遮断器を設置する。漏電遮断器は、正規の電気回路の外に電気が漏れ出たことを感知して回路を遮断する装置である。これによって、漏電による感電が起こったとしても、感電の時間をごく短い間に留めることができる。
- 確実に絶縁を行い、電流が流れる部位が直接露出しないようにする。例えば、配線は絶縁体の素材で被覆されたものを使うべきであり、また導線の端子部分が露出しないように注意しなければならない。
- 分解の途中で電子回路に直接触らないように注意する。特に大電流が流れている機器の場合、分解の際に感電による重傷を負う恐れがある。
参考文献:
- https://www.msdmanuals.com/ja-jp/%E3%83%9B%E3%83%BC%E3%83%A0/25-%E5%A4%96%E5%82%B7%E3%81%A8%E4%B8%AD%E6%AF%92/%E6%84%9F%E9%9B%BB%E3%82%84%E8%90%BD%E9%9B%B7%E3%81%AB%E3%82%88%E3%82%8B%E5%A4%96%E5%82%B7/%E6%84%9F%E9%9B%BB%E3%81%AB%E3%82%88%E3%82%8B%E5%A4%96%E5%82%B7
- https://www.msdmanuals.com/ja-jp/%E3%83%97%E3%83%AD%E3%83%95%E3%82%A7%E3%83%83%E3%82%B7%E3%83%A7%E3%83%8A%E3%83%AB/22-%E5%A4%96%E5%82%B7%E3%81%A8%E4%B8%AD%E6%AF%92/%E9%9B%BB%E6%92%83%E5%82%B7%E3%81%8A%E3%82%88%E3%81%B3%E9%9B%B7%E6%92%83%E5%82%B7/%E9%9B%BB%E6%92%83%E5%82%B7
- 『やさしく学ぶ電気安全NOW』1993, 小原幸雄, オーム社
所感
電子工作をやる訳ですから感電について知っておくことは当然必要ですよね。MSDマニュアルの議論を参考にして推論の筋道を立てました。 回答締切後になって、交流の方が危険な背景として細胞膜のイオンチャネルが関係しているらしいという話も聞きました。生物学に明るい方はその方面で回答をまとめてみるのもアリなのではないでしょうか。
第4問
GPIOに5.0Vを入力しようと思います。この機器は正常に動作しますか?
正常に動作しない。rp2040-datasheet.pdf p.638 の Table 632 にデジタルIOピンの入力電圧の最大値の記述があり、それには「Input Voltage High IOVDD+0.3」と記載されている。ここでIOVDDとはデジタルGPIO用電源で、その絶対最大定格は同じページの Table 629 に「3.63V」であると書かれている。したがって、入力電圧の最大値は高々3.93Vであるので、5.0Vの入力電圧では正常に動作しないと考えられる。しかも、5.0Vは電源電圧よりも高い電位なので、この電圧をGPIOに入力するとポートから電源に電流が流れ、マイコンを破壊してしまう可能性すらある。
この機器でSPI通信は使用できますか?
使用できる。rp2040-product-brief.pdf の p.3 に "2 × SPI controllers" との記述があり、SPIコントローラが搭載されていることが分かる。
IOVDDとDVDDの違いを説明してください
IOVDDはデジタルGPIO用電源のピンであり、公称電圧は1.8V~3.3Vとなっている。DVDDは公称電圧1.1Vのデジタルコア電源で、VREG_VOUT(内蔵コア電圧レギュレータ用電源出力のピン)などの電源に接続することができる。
SWDポートを使うと何ができますか?
SWDとは、Serial Wire Debugの略で、2本の信号線を用いてICの内部回路と通信を行うための汎用的なインタフェースである。ここにケーブルを接続することでプロセッサのリモートデバッグを行うことが出来る(出典: rp2040-product-brief.pdf p.4, rp2040-datasheet.pdf p.11)。 SWDポートを用いたデバッグ方法の詳細については、rp2040-datasheet.pdf の p.61 "2.2.3.4. Debug" 節に詳しい記載がある。それによると、このSWDポートは以下のような機能を提供している:
- ファームウェアをSRAMやフラッシュメモリにロードする
- プロセッサの動作をコントロールし、実行・一時停止・ブレークポイントの設定を始めとするARMコアのデバッグ機能を操作する
- プロセッサのArchitectural state(≒レジスタ)にアクセスする
- システムバスを経由して、メモリやメモリマップドI/Oにアクセスする
GPIO 1ポートから標準で何mA出力できますか?またGPIO合計で最大何mAまでの電流を出力できますか?(ただしQSPIポートで使用する電流は考慮しないものとします)
rp2040-datasheet.pdf の p.641 に "the sum of all the IO currents being sourced (i.e. when outputs are being driven high) from the IOVDD bank (essentially the GPIO and QSPI pins), must not exceed IIOVDD_MAX." という記述があり、GPIOポートとQSPIポートから供給される全てのIO電流の合計が、IIOVDD_MAX (=50mA, p.639 の table 632 に記載) を超えてはならないことが分かる。しかし、QSPIポートを考慮しないGPIOの最大および標準の出力電流は、データシートのどこから読み取ればよいのか特定することが出来なかった。
参考文献
- 『Make: Elecrtonics 第2版』Charles Platt, O'Reilly Japan, 2020
- http://www.tokudenkairo.co.jp/jtag/adv2018/08.php
- https://deviceplus.jp/raspberrypi/raspberrypi-gpio/
- https://www.analog.com/jp/analog-dialogue/raqs/raq-issue-50.html
所感
これも「こういうマイコン使うから仕様確認してね」「データシートの見方は大丈夫かな?」という感じっぽいですね。GPIOの仕様を読み解くのにだいぶ苦労しました。出力電流についてはデータシートを見ているうちにこんがらがってしまったので、その時点で把握できたことを書きました。
第5問
証明の名前について
解答
技術基準適合証明
考えたこと
まず電波法の条文を見て、電波法の総則で定義を確認した上で、電波を発射する装置に関する証明についての記述を探した。
- 電波法第二条によると、
- 「電波」とは、三百万メガヘルツ以下の周波数の電磁波を指す。
- 電波を送受信するための電気的設備を「無線設備」という。
- 無線設備及び無線設備の操作を行う者の総体を「無線局」という。ただし、受信のみを目的とするものを含まない。
- 同法第四条によると、無線局を開設しようとする者は、4つの例外を除き、総務大臣の免許を受けなければならない。
- 同法第三章は無線設備が満たさなくてはならない技術基準を定めている。
- 同法第三十八条の二の二によると、小規模な無線局に使用するための無線設備であって総務省令で定めるものを「特定無線設備」という。
- 同法第三十八条の二の二によると、同法第三章の基準に適合している無線設備には「技術基準適合証明」という証明が与えられる。
つまり、電波を発射するための装置を利用するには、原則として総務大臣から免許を交付される必要があること、無線装置は電波法に規定されている技術基準を満たしていなければならないこと、技術基準を満たしている無線装置にはその証明が与えられることがわかる。
電波法の規定では、次の場合に当てはまる無線機器には、それを示す適合表示を付与する必要がある。
- 登録証明機関又は承認証明機関が技術基準適合証明をした場合
- 登録証明機関又は承認証明機関により工事設計認証を受けた者がその認証に係る工事設計に基づく無線設備について検査等の義務を履行した場合
- 技術基準適合自己確認をし、総務大臣に所要自己を届け出た製造業者又は輸入業者が、届出工事設計に基づく無線設備について検査等の義務を履行した場合
ここで、問題文の指示は「電波を発射する装置を日本国内で合法的に使用する」ために必要な無線機に与えられる「電波を発射する電波法で定められた基準に適合しているという証明」の名前を答える、ということであった。 上で見た「技術基準適合証明」の電波法上の定義は、問題文で与えられた「証明」と内容が一致するので、答えるべき「証明」とは「技術基準適合証明」のことであると考えられる。
参考文献:
- https://elaws.e-gov.go.jp/document?lawid=325AC0000000131
- https://elaws.e-gov.go.jp/document?lawid=325M50080000014
- https://www.tele.soumu.go.jp/j/adm/monitoring/summary/qa/giteki_mark/index.htm
- https://www.tele.soumu.go.jp/j/sys/equ/tech/
- https://www.dsk.or.jp/dskwiki/index.php?%E9%81%A9%E5%90%88%E8%A1%A8%E7%A4%BA%E7%84%A1%E7%B7%9A%E8%A8%AD%E5%82%99
- https://www.ieice.org/~cs-edit/magazine/ieice/alldata/Bplus31_all.pdf
非純正ファームウェアで証明が無効になる理由について
無線ルータなどの特定無線設備の技術基準適合証明を受けるためには、登録証明機関又は承認証明機関の検証を受けるか、製造業者・輸入業者自らが検証して技術基準適合自己確認を行い総務大臣に届け出る必要がある。だが、証明を受けるための検証の際には純正ファームウェアのみで試験を行うと考えられる。つまり、非純正ファームウェアを導入した特定無線設備は技術基準適合証明の検証環境と異なるため、電波法の技術基準を満たさない恐れがある。したがって、非純正ファームウェアでは技術基準適合証明が無効になる恐れがある。(245文字)
所感
設問を見た時点でまあ技適のことを言ってるんだろうなということは分かるので、電波法の条文を読んで「なぜ技適だと言えるのか」を裏付けるという方針で考えました。条文の読み方については、学科の選択科目で取っていた法律学入門の授業の経験が役に立ちました。
エレラボDiscordの運用とこれから
この記事は、上智大学エレラボ Advent Calendar 2021 第1日目の記事です。
おはようございます。エレラボ部長のstepney141です。
エレラボでは、基本的にDiscord(およびLINE)を使って連絡を取り合っています。 この記事では、エレラボDiscordの管理に関してポエムを書き連ねていきます。
私とDiscordとの馴れ初め
私が初めてDiscordを使い始めたのは2017年1月(当時高校一年生)のことでした。
私は当時、通っていた中高のクラブ活動で「コンピュータ部」なる異常独身男性予備軍互助組織に所属しており、そこの先輩が部のDiscordサーバを作ったのがきっかけでした(ちなみにそれまでは、Skypeのグループチャットのテキストメッセージ機能を使っていました)。
今までに経験のないDiscordの多機能さに私が慣れていなかったことも大きいでしょうが、当時のAndroid版DiscordアプリのUIはあまり使いやすいものではなく、
当時の私は「操作性ではskypeやLINEに劣っていると思う、少なくともスマホ版では」などと考えていました。
ですが、Discordで他の部員と駄弁る日を過ごすうちに段々と操作にも慣れて、複雑なUIもDiscordのアップデートに伴って徐々に整理されていきました。
そのうちLINEやSkypeにはないチャンネル機能やロール機能などの便利さに気づいた私は、すっかりDiscordを便利なアプリだと感じるようになっていきました。
Discordに日本リージョンがなく、日本に最も近いのがシンガポールリージョンだった、そんな頃の話です。
時が経つにつれてコンピュータ部のサーバのチャンネル数や会話量はどんどん増えていき、それに従ってチャンネル構成や管理体系もより洗練されたものになっていきました。
Pythonをやっている部員が管理用のbotを作ったり、なぜかサーバに居座り続けているOBが自作のゲームbotを追加したりしたことで、色々と便利にもなりました。
今では10カテゴリにまたがって70以上のチャンネルが作られ、79人ものメンバーが参加しているという、中高の部活のチャットとしてはそれなりの規模と思われるサーバになりました。
こんな感じで、私は「Discordサーバの居心地の良さ・使い勝手の良さは、コミュニティにとって重要な要素である」という考えを持つようになりました。
はじめに混沌があった
やがて私は高校を卒業し、色々あって大学に入学すると、オンライン授業のせいで体重が単調増加を続ける日々の真っ最中にエレラボに入部し、エレラボのDiscordサーバに参加しました。
ですが、当時のエレラボDiscordサーバは非常に使いづらく、改善の余地という概念を50kgほど集めて凝り固めたような姿をしていました。
当時の私が書いたメモがこちらです:
・雑談チャンネルと真面目な事務関係のチャンネルが同じカテゴリにある ・学年権限がぐちゃぐちゃ ・管理者が誰なのかすぐに分からない(少なくとも新しく参加した人間にとっては) ・自己紹介チャンネルがなかった(私が提案して初めてできた) ・説明書チャンネルがなかった(同上) ・お知らせチャンネルがない カテゴリ分け、 ・テキストチャット ・ボイスチャット ・ハッカソン ・学園祭関係 ・ハードウェア関係(?) ・オンラインハッカソン ・その他カテゴリに入ってないチャンネルが、テキストチャット・ボイスチャット含めて複数あり

補正をかけまくっているのでかなり見づらくなってしまっているのですが、当時のロールの構成です(私が2年生になってある程度の管理権限をもらった時に撮ったものです)。 「新入生」と「1年」が同時に存在している他、ロールの順序も全く整理されていない状態になっています。
ロールやチャンネルの情報は、コミュニティに新しく参加した人間にとって、そのサーバにおいて社会的な立ち振舞いをするにはどうすれば良いのかを把握するために重要でもあります。 また、様々なチャンネルを整備して「この話題にはこのチャンネルを使ってください」と促すことで、人間関係の構築やコミュニケーションがスムーズになりやすくなる面もあるかと思います。
ですが、ただの新入生の私にとって、これらの使いにくさを逐一指摘するのは非常にためらわれることでした。 Covid-19の蔓延で対面でのサークル活動ができない中、Discordでは雑談すらほとんどされることがない状況でした。 お互いに人となりを知る手段が全くない中で、新入生が色々と要望を出すことで上回生の心証を損ねない自信がなかったのです。
心証の問題については後に、上回生と個人的なやりとりをして人間関係を構築したり、Advent Calendar 2020の開催を提案して自分でも色々と記事を書いたり、立候補してエレラボの副部長になったりしたことによって、ある程度は解決したと思います。
サーバの整理とbotの開発
B2になって副部長に就任した私は、Discordサーバの整備に着手しました。
- 話題ごとにチャンネルをカテゴリ分け
- 使われていない廃墟チャンネルをメインのカテゴリから追放、アーカイブ化
- ロール設定を整備し、一般部員が操作できる内容を増やす
などの作業を実行し、それなりに使いやすいと思われるDiscordサーバの構築に勤しみました。
また、管理を補助するためのDiscord Botを自作しました。
上回生のご協力も頂き、色々と面白い機能(エレラボ内製の部費会計用Webサービスとの連携、エレラボGoogleアカウントへのログインを円滑にするための二段階認証コード自動生成機能など)も実装することができました。 以前からDiscord Botを作ってみたいと思っていた私にとっては、趣味と実益を兼ねた面白い体験になりました。
今後の課題
現在残っている課題は、主に2つあります。
- DiscordとLINEとの併用体制の使いにくさ
- 雑談の少なさ
まず 1. についてです。
現在エレラボでは、部内の連絡手段としてLINEグループチャットとDiscordサーバを併用する体制を取っています。
しかし、コロナ禍で緊急の連絡をせざるを得ないこともあるこのご時世、連絡手段が2つに分散しているという現状は何かと不便なのです。
加えて会話をする場所が分かれていると、部員同士の雑談や部員が提供してくれる有益な情報もまた分散してしまい、コミュニケーションが取りづらくなるという無視できない弊害もあります。
Discordは
- LINEよりも機能が多く
- ロール機能とチャンネル機能による柔軟な権限管理とチャットシステム
- Zoomのような画面共有機能
- 複数端末でのログインが円滑で
- 機種変更時にチャットの履歴が飛んだりしない
など、LINEにはないメリットが多数ある素晴らしいサービスであり、個人的にはできればDiscordに統一したいと考えています。
しかし同時に、
- Discordに慣れていない人には操作がとっつきにくい
- LINEを常用している人の方が多い
という点から、Discord一本に切り替えるというのも無理があります。
Discordのボイスチャットから抜けようとしてサーバ自体から脱退してしまった人を観測し、「慣れないとDiscordの操作は難しいよな」「やはりLINEを排してDiscord一本でやっていくのは厳しそうだな」という気持ちになった
— ゆみや (@stepney141) 2021年8月15日
基本的にはDiscordをメインとしてLINEには書き込みをせず、サーバ障害などの不測の事態によってDiscordが使えなくなったときのための予備として、LINEも残していくのが無難な選択肢なのではないかと考えている今日この頃です。
次は2.についてです。
ワクチンの接種が進んで感染者数も落ち着きを見せ始めたことによって、弊学では11月から対面での課外活動が解禁されました(12月1日からは飲食・宿泊を伴う活動も解禁されます)。これに合わせて、エレラボも久しぶりに11月中旬から対面活動を再開しました。
いくらDiscordを使いやすいように整備したからと言っても、それに先立つものとして顔を合わせた対面活動ができなければ、良いコミュニティを作ることは難しいです(DiscordやTwitterを介した顔の見えないコミュニケーションだけで親密な人間関係を構築できるタイプの人も世の中にはいますが、世間の多くの人々は顔の見えるコミュニケーションを重視します)。
エレラボは2018年にできたばかりのごく新しいサークルです。 活動の基礎すら定まっていない状況下でコロナ禍に直面し、非常に難しい局面に立たされています。 対面活動とオンラインでのやり取りの両立によって、多くの部員にとってエレラボが少しでも居心地が良くて楽しい場所であれるように、態勢を整えていきたいと考えています。
グラフ電卓TI-Nspireのネイティブ開発環境「Ndless SDK」をDockerで導入する
以前、このような記事を書きました。
あれから数年が経ち、Dockerという大変便利なものをちょくちょく触る機会が訪れるようになりました。
そこで趣味(Ndless SDKを簡単に導入したい)と実益(Dockerの練習をしたい)を兼ねて、Ndlessの開発環境をDocker Composeで手軽に構築できるようにしてみました。
Dockerfileやdocker-compose.yml一式を収めたGitHubリポジトリはこちらです。
使い方に関しては全てREADME.mdに書いてあるので特に触れることはないです。
大変だったこと
主にNdless SDKのドキュメントが不親切すぎることから来るトラブルに何度も見舞われたのがしんどかったです。
最初、Ndlessのドキュメントに書かれている導入ガイドをそのままDockerfileに落とし込んでいたのですが、 いざコンテナを構築してみると途中でシェルが異常終了し、起動に失敗するという事態に見舞われました。
twitter.comDocker何もわからない pic.twitter.com/bzKPlwXdy1
— ゆみや (@stepney141) 2020年12月27日
twitter.comこれ、git cloneしてきたシェルスクリプト(build_toolchain.sh)のうち、17行目から22行目あたりまでのどこかでエラーが発生しているのが原因らしいということまで把握した https://t.co/r4e30jeDhL
— ゆみや (@stepney141) 2021年1月10日
デバッグしていくうちに、環境構築の際に実行されるシェルスクリプトの特定の行でエラーが発生していることが分かりました。 最初は原因としてbashとshの互換性の問題を疑っていたのですが、 結局のところ「必要なものとしてPythonを明記していないにも関わらず、シェルスクリプト内でPython3の存在を前提とした動作をしていたせい」だと分かりました。つらい。 まあ一ヶ月近くも原因に思い足らなかった私もどうかと思いますが。
その後も色々なビルドエラーに見舞われましたが、いずれもドキュメントをあてにせずエラーログを参照し、すべてドキュメントに明記されていない依存パッケージが入っていなかったせいであることを突き止めました。つらい。
ともあれ開発環境も整ったことですし、Nspireでのネイティブ開発を進めていきたいと思います。