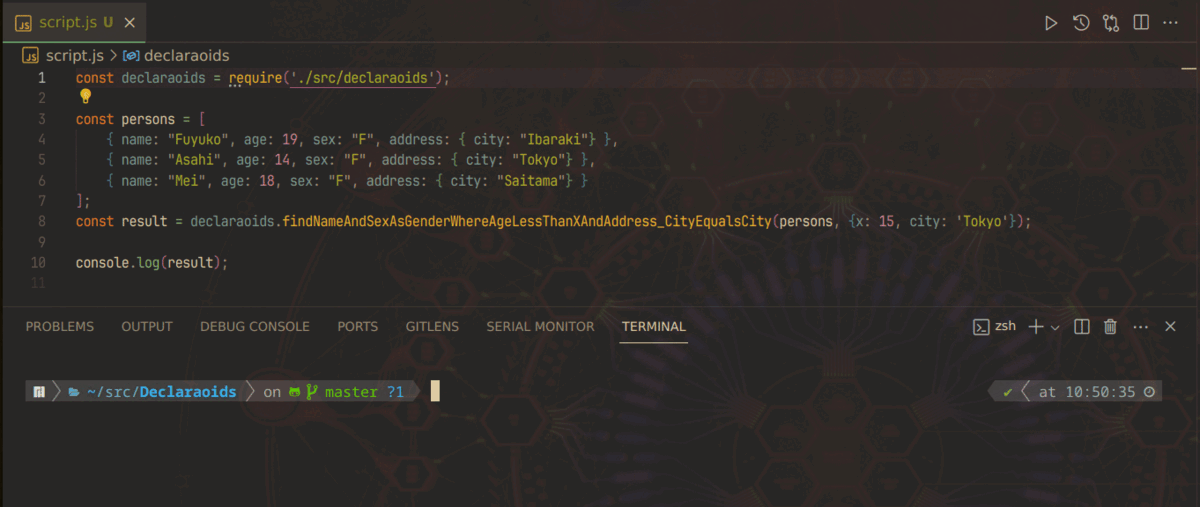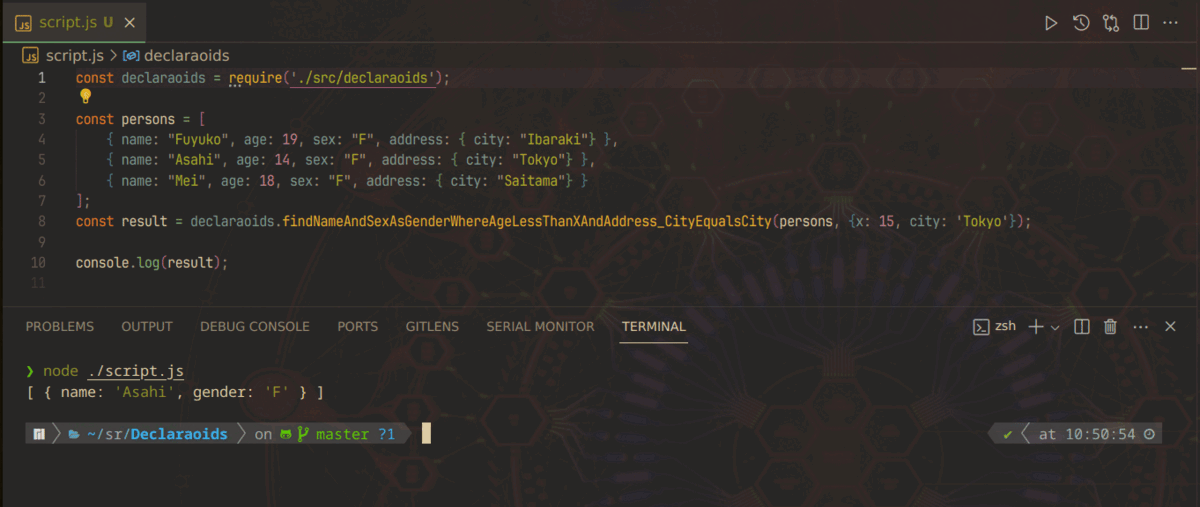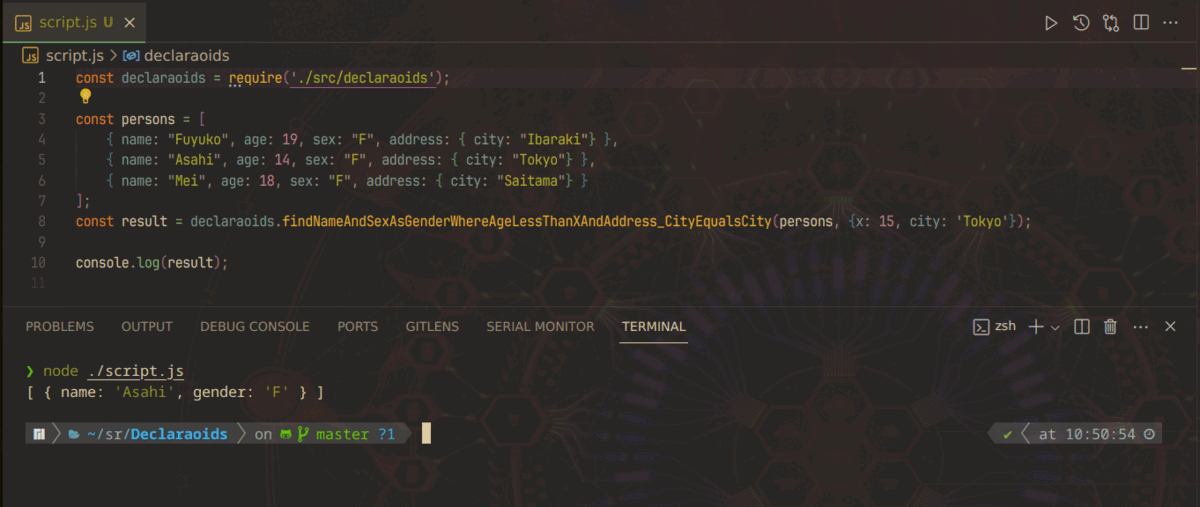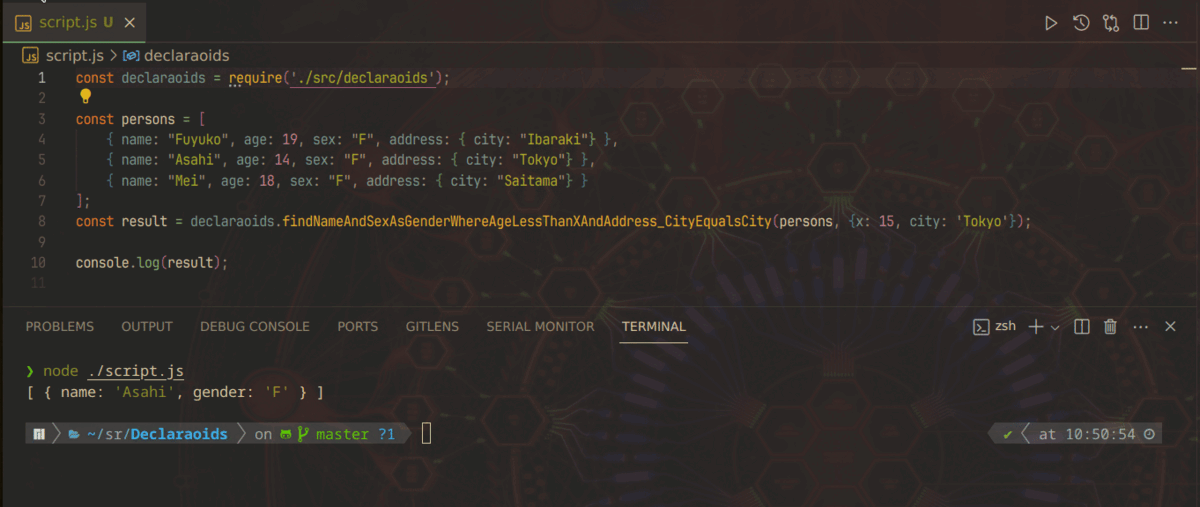
この記事は、「LipersInSlums Advent Calendar 2023」第14日目の記事です。
昨日の記事は、ターニャ・デグレ チャフ さんの「Monadic Parserの俺的理解 」でした。
adventar.org
知らない人のために触れておくと、LipersInSlums とは謎の Discord サーバです。
旧 Twitter ヘビーユーザーの計算機オタクがなぜかいっぱい集まっているという特徴があります。住民からは「スラム」と通称されています。
具体的にどんなところがスラム街っぽいのかについては、melovilijuさんの5日目の記事を読めば何となくわかると思います。
lipersinslums.github.io
はじめに
突然ですが、皆さんは積読 してますか?私はしてます。
受験生の頃に神保町の古本市でストレスを紛らわすことを覚えて以降、ろくに読んでない本がまだ大量にあるのになぜか色々な本屋を巡っては、インターン の給与の大半を紙の山に変換するという日々を送るようになりました。
本を渉猟している間の脳内は「面白そうな本がこんなにたくさん並んでるぞ!ここに住みてえ!」という多幸感で満ち溢れているのですが、いざレジに並んでバーコードリーダ ーの電子音が耳に入ってくると、快楽に代わって絶起 時にも似た謎の虚無感が襲いかかってきます。
有料の紙袋を手に退店し、下りエス カレータの手すりに体重を預けているうちに頭をもたげるのは「また買っちゃったな、早く読まなきゃ」という義務感です。
「最近の新刊書は店頭に並んでいるうちに買わなきゃすぐに絶版になるんだからし ょうがない!!!」と自己正当化を図りながら自動ドアをくぐり、外の冷たい空気を吸うと、喪失感のいくばくかは充実感へスーッと変換されます。
陰と陽両方の感情を胸に抱きつつ、自宅の床の空きスペースを頭の中で勘定しようとすると、途端に丸善 のロゴ入り紙袋が子泣き爺のようにズシリと重量を増し始めるのです。
丸善 丸の内本店の店内には、何か人を恍惚とさせるような謎の物質が散布されているのかもしれません。
個人的には大麻 よりも先にあちらを法規制すべきだと思います。
なお、新刊書だけでなく古本収集にも手を出している私の本棚は既にキャパオーバーしているため、家族の本棚を間借りしています。
約2年前に行った京都旅行で一番楽しかったレジャーは、日程を丸一日費やしての古本屋巡りでした。
「積読 本は謎のエネルギー波を出しており、持ち主が寝ている間に脳を活性化させてくれる」なんて話もありますが、少なくとも財布と精神の健康にはまるでよろしくないと思います。
そんな書痴気味の私にとってなくてはならないのが、蔵書管理ツールです。
読んだ本や積読 本が多くなってくると、ダブリ購入防止のため蔵書を良い感じに管理したくなってくるものですよね。
私は4年ほど前から「読書メーター 」というWebサービス を使って蔵書・読書状況を管理しています。
bookmeter.com
私が読書管理の中で最も重視している営みは、今ある蔵書の管理というよりも『読みたい本の管理』です。
書店の棚・旧Twitter のタイムライン・面白そうな授業のシラバス などを見ていると、面白そうな雰囲気の本に思いがけず出会うことがしばしばあります。
そんな時はいわばToDoリストのような感覚で、読書メーター を開いて『読みたい本』に登録しています。
この習慣を4年ほど続けているうちに、いつの間にか『読みたい本』が800冊を数えるようになりました(2023年12月現在)。
ここで話はB1の冬休み(『読みたい本』がまだ300冊くらいだった頃)に遡ります。
その頃の私は、読書メーター だけでは『読みたい本』が身近な図書館に置いてあるかが分からない
当時は何度目かの緊急事態宣言が明けて、キャンパスへの入構規制が少し緩和されていた頃です。
入学以来初めて大学図書館 をそこそこ自由に使えるようになったことで、「この本、大学図書館 に置いてあったのかよ…Amazon から自腹で買う必要なかったじゃん…」 という悲劇にたびたび見舞われるようになっていました。
まして高額な専門書ともなると、自分に合わない本と知らずに買ってしまった時の損失は本当にバカになりません(金銭的にも精神的にも)。合うかどうかも分からないのに高額な本を買う方がバカだと? うるせぇ〜!!
そもそも、図書館の資料購入費や維持管理費は(少なくともある程度は)学費で賄われているはずです。言い換えれば、図書館の本は実質学生の金で買われたようなもの。
ということは、実質的には私の所有物…すなわち私の積読 本と言っても全く過言ではないでしょう。
何万冊もの積読 本が所有しているにも拘らず、その内容を自分では全く把握できていない! なんと嘆かわしいことでしょう……。これこそ、技術の力でどうにかすべきです!
ともかく、そうなると当然こういうモチベーションが湧いてきます。
というわけで、そういうツールを自分で作って現在まで運用を続けている話について、B1~B2の頃の自分を振り返る意味も込めて書いてみます。
TL;DR
あらかじめお断りしておくと、技術的に高度なことは一切せず、あるものを素直に組み合わせているだけです。
言語は JavaScript → TypeScript (+ Node.js)
いろんな WebAPI を組み合わせ、書誌情報と所蔵の有無を調べている
GitHub Actions 上で稼働しているデータは CSV ファイルとして GitHub で管理
『読みたい本』リストを大学図書館 で見ている様子
なお、完成品はこちらです。
github.com
やったこと
技術選定
求めている機能はだいたいこんな感じでした。
読書メーター の『読みたい本』が大学図書館 にあるかどうかをリスト化したい書名だけじゃなく、著者とか出版年とかも見れるようにしたい
図書館の中でもスマホ でパッと見れるようにしたい
「大学にある本」「大学にない本」を分けて見れるようにしたい
やるべきことはこんな感じです。
読書メーター から『読みたい本』の情報をエクスポートするどこかから書誌情報を取ってくる
どこかから大学図書館 の所蔵検索をする
アプリケーションをどこかにデプロイして定時実行する
1. 読書メーター から『読みたい本』の情報をエクスポートする
読書メーター から直接『読みたい本』の情報を出力できれば良いのですが、読書メーター にそうした機能は備わっていません。
したがって、読書メーター をスクレイピング して『読みたい本』の情報を自力で回収する必要があります。
当時の私は Node.js と puppeteer を使った Web E2E テストを書いて給料を貰っていたので、自然な発想として、ここでも使い慣れた puppeteer を使うことにしました。
なお、作った当時は生の JavaScript で書いていましたが、今年に入ってから TypeScript で全面的に書き直しました。
まず、読書メーター から具体的に何の情報を取ってくるべきかという点が重要です。
DevTools で読書メーター の『読みたい本』一覧ページの中身を確認してみると、次のようになっていました(画像は2023年12月撮影)。
ここから個別の本を識別できそうな要素を選び、なんらかの方法で対応する本の書誌情報を取ってくることにしました。
書名は途中までしか表示されないので、使えそうな情報は Amazon 商品ページへの外部リンク・個別書籍ページへの内部リンクに限られます。
Amazon の商品情報を直接取得できる WebAPI は一応存在するようですが、どうも Amazon と連携して EC サイトやら何やらを作りたい事業主のためのサービスらしく、利用条件が厳しかったため断念しました。
jsstudy.hatenablog.com
hnavi.co.jp
Amazon の商品ページを直接スクレイピング して商品情報を取ってくるという手もありますが、手間が増えるので一旦保留。
しばらく DevTools をグッと睨んでいたところ、Amazon への外部リンク URL に ASIN コードが含まれていることに気づきました。
前述したように、ASINコードとは Amazon における商品の識別コードです。ASINコードの命名規則 は公表されていませんが、紙の書籍商品ではISBN-10コードがそのまま ASIN コードとして扱われることが知られています(Kindle 電子書籍 には紙書籍版と異なるASINコードが採番されます)。
つまり、紙の書籍であれば、読書メーター の URL 文字列を正規表現 に食わせるだけでその本の ISBN をゲットできるということです。
ISBN さえ分かれば、何らかの WebAPI を使って書誌情報もゲットできそうですね。Amazon の商品ページを直接読むよりも明らかに簡単そうです。
万が一、アカウントをBANされたり神奈川県警に逮捕されたりしたら困るので、読書メーター の利用規約 も確認することにしました。
第9条は「故意に本サービスのサーバ又はネットワークへ著しく負荷をかける行為(14号)」および「当社又は、第三者 の著作権 、商標権などの知的財産権 を侵害する行為、又は侵害するおそれのある行為(18号)」を禁じています。
しかし、サービスに負荷をかけない範囲でのスクレイピング 行為は禁じていません。また、取得しようとしているのは単なるURL文字列なので、誰かの知的財産権 を侵害することもありません。
bookmeter.com
読書メーター では同じ出版物であっても紙の書籍版と Kindle 版とでページを区別しているため、『読みたい本』に紙書籍版ではなく Kindle 版を誤登録してしまいやすい構造になっています。
このため、ツールを動かし始めた当初は、Kindle 版の ASIN コードのまま書誌情報を検索しようとしてしまい「そんな本はねえよ」とエラーを吐かれる事象が頻発していました。
ただし、ツールを動かし始めてからし ばらくして読書メーター の検索機能が改修され、紙書籍版が優先的に上位に来るようになったため、この問題に見舞われることは少なくなりました。
読書メーター公式ブログ — ブラウザ版 書誌検索オプション アップデートのお知らせ
2. 書誌情報を取ってくる
ISBN から書誌情報を取得する WebAPI には、主に以下のものがあります。
どれも一長一短なので、私のコードではこれらを組み合わせて使用しています。
本1冊の書誌情報は下のBook型のオブジェクトとして管理し、API を叩きながらBookオブジェクトを更新する形になっています。
Book は BookList に蓄積されていき、最終的に BookList の中身をCSV 形式で出力して処理を終えます。
後述する問題から、BookListオブジェクトの主キーとしては、ISBNではなく読書メーター のURLを使っています。
type Book = {
bookmeter_url: string ;
isbn_or_asin: ISBN10 | ASIN | null ;
book_title: string ;
author: string ;
publisher: string ;
published_date: string ;
central_opac_link: string ;
mathlib_opac_link: string ;
} & {
[ key in ExistIn] : "Yes" | "No" ;
} ;
type BookList = Map < string , Book>;
type ExistIn = `exist_in_ ${ CiniiTargetOrgs} ` ;
type CiniiTargetOrgs = (typeof CINII_TARGET_TAGS) [ number ] ;
const CINII_TARGET_TAGS = [ "Sophia" , "UTokyo" ] as const ;
ISBNを主キーとして使うことの問題
日本の出版業界におけるISBNの運用状況は、はっきり言って非常にいい加減 です。この問題の大変わかりやすい説明として、以下の一連のツイート群を提示しておきます。
上のツイートでも触れられていますが、2016年には岩波書店 が同じ本の旧訳・新訳でISBNを使い回していることが判明し、Twitter の読書趣味界隈(+プログラマ 界隈の一部)で問題になりました。
togetter.com
stonebeach-dakar.hatenablog.com
こうした問題のため、本当はISBNを書誌情報の主キーとして実用することはできません 。
しかしそれにもかかわらず、書誌情報を WebAPI として取ってくる際は ISBN を実質的な主キーとして用いざるを得ません。
そのため、本ツールでは前回の出力結果を活用できず、「実行する度に毎回全ての書誌情報を新しく取ってくる」という効率の悪い実装を強いられる状況になっています(同じ API に同じ ISBN をリクエス トしても、返ってくる書誌情報がいつも同じとは限らず、しかも変化が起こるタイミングはこちらから観測できないため)。
OpenBD
みんな大好き株式会社カーリルと、出版業界団体の「一般社団法人 版元ドットコム」が共同で提供している書誌情報API です。
非常に多様な書誌情報を提供しているのが魅力的です。
openbd.jp
最近の本の情報は8割方ここで取れますが、古い本・一部の出版社の本は網羅されていない場合があります。
また、今年になって書誌情報の有力な提供元(別の出版業界団体)と深刻な仲違いをしたらしく、書籍の網羅率や取得可能な書誌情報の量が以前よりも減っています。
このAPI の最大の特徴は、「全件取得やデータ同期を推奨するAPI設計(大量アクセス対応)」を謳っていることです。
運営元のお言葉に甘えて、1回のリクエス トで『読みたい本』全ての書誌情報を一度に検索する贅沢な使い方をしています。
const bulkFetchOpenBD = async ( bookList: BookList) : Promise < BiblioInfoStatus[] > => {
const bulkTargetIsbns = [ ...bookList.values() ] .map(( bookmeter) => bookmeter[ "isbn_or_asin" ] ) .toString();
const bookmeterKeys = Array .from( bookList.keys());
const response: AxiosResponse< OpenBdResponse> = await axios( {
method: "get" ,
url: `https://api.openbd.jp/v1/get?isbn= ${ bulkTargetIsbns} ` ,
responseType: "json"
} );
const results = [] ;
for ( const [ bookmeterURL, bookResp] of zip( bookmeterKeys, response.data)) {
if ( bookResp === null ) {
const statusText: BiblioinfoErrorStatus = "Not_found_in_OpenBD" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
results.push( {
book: { ...bookList.get( bookmeterURL) ! , ...part } ,
isFound: false
} );
} else {
const bookinfo = bookResp.summary;
const part = {
book_title: bookinfo.title ?? "" ,
author: bookinfo.author ?? "" ,
publisher: bookinfo.publisher ?? "" ,
published_date: bookinfo.pubdate ?? ""
} ;
results.push( {
book: { ...bookList.get( bookmeterURL) ! , ...part } ,
isFound: true
} );
}
}
return results;
} ;
上述の通り、OpenBDだけでは『読みたい本』全ての書誌情報を得ることができないため、後述する他サービスからの情報で不足分を補完しています。
みんな大好き国立国会図書館 の資料検索機能のAPI です。
iss.ndl.go.jp
さすがに国会図書館 だけあって、ISBN付きの和書なら十中八九ヒットします。
が、かつてのWeb2.0 時代の遺産というべきか、レスポンスがXML 形式です。私はfast-xml -parserでパースしています。
github.com
const fetchNDL: FetchBiblioInfo = async ( book: Book) : Promise < BiblioInfoStatus> => {
const isbn = book[ "isbn_or_asin" ] ;
if ( isbn === null || isbn === undefined ) {
const statusText: BiblioinfoErrorStatus = "INVALID_ISBN" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
return {
book: { ...book, ...part } ,
isFound: false
} ;
}
const response: AxiosResponse< string > = await axios( {
url: `https://iss.ndl.go.jp/api/opensearch?isbn= ${ isbn} ` ,
responseType: "text"
} );
const json_resp = fxp.parse( response.data) as NdlResponseJson;
const ndlResp = json_resp.rss.channel;
if ( "item" in ndlResp) {
const bookinfo = Array .isArray( ndlResp.item) ? ndlResp.item[ 0 ] : ndlResp.item;
const part = {
book_title: bookinfo[ "title" ] ?? "" ,
author: bookinfo[ "author" ] ?? "" ,
publisher: bookinfo[ "dc:publisher" ] ?? "" ,
published_date: bookinfo[ "pubDate" ] ?? ""
} ;
return {
book: { ...book, ...part } ,
isFound: true
} ;
} else {
const statusText: BiblioinfoErrorStatus = "Not_found_in_NDL" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
return {
book: { ...book, ...part } ,
isFound: false
} ;
}
} ;
みんな大好きGoogle が提供しているGoogle BooksというサービスのAPI です。
developers.google.com
1日に1000回までという利用上限があるため、使いどころをかなり考えて叩く必要があります。
今のところ、OpenBDや国会図書館 サーチでは手薄になっている洋書の情報を補う目的で採用しています。
const fetchGoogleBooks: FetchBiblioInfo = async ( book: Book) : Promise < BiblioInfoStatus> => {
const isbn = book[ "isbn_or_asin" ] ;
if ( isbn === null || isbn === undefined ) {
const statusText: BiblioinfoErrorStatus = "INVALID_ISBN" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
return {
book: { ...book, ...part } ,
isFound: false
} ;
}
const response: AxiosResponse< GoogleBookApiResponse> = await axios( {
method: "get" ,
url: `https://www.googleapis.com/books/v1/volumes?q=isbn: ${ isbn} &key= ${ google_books_api_key} ` ,
responseType: "json"
} );
const json = response.data;
if ( json.totalItems !== 0 && json.items !== undefined ) {
const bookinfo = json.items[ 0 ] .volumeInfo;
const part = {
book_title: ` ${ bookinfo.title}${ bookinfo.subtitle === undefined ? "" : " " + bookinfo.subtitle} ` ,
author: bookinfo.authors?.toString() ?? "" ,
publisher: bookinfo.publisher ?? "" ,
published_date: bookinfo.publishedDate ?? ""
} ;
return {
book: { ...book, ...part } ,
isFound: true
} ;
} else {
const statusText: BiblioinfoErrorStatus = "Not_found_in_GoogleBooks" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
return {
book: { ...book, ...part } ,
isFound: false
} ;
}
} ;
みんな大好き楽天 が提供している楽天ブックス というサービスのAPI です。
ECサイト の商品検索API なので、和書だけでなく雑誌やCDや洋書にも対応しているのが強みです。
webservice.rakuten.co.jp
現在のところは上述の3つで十分な情報を取れているので採用していませんが、そのうち雑誌検索用に使おうかと考えています。
高速化のために
ここまで述べてきた通り、このツールは何種類もの WebAPI を合計で数百回ほど叩くことによって実現されています。
しかし、何も考えず直列的に API を叩くと、読書メーター の走査開始からCSV ファイルの出力までに30分は掛かってしまいます(リクエス ト1回につき1~2秒のインターバルを置くと、さらに時間がかかります)。
そのため、こちらの記事を参考に複数のPromiseを同時並行で処理しています。
zenn.dev
これが功を奏し、API リクエス トのインターバル込みでも12~13分で処理を終わらせられるようになりました。
const fetchBiblioInfo = async ( booklist: BookList) : Promise < BookList> => {
const mathLibIsbnList = await configMathlibBookList( "ja" );
const updatedBookList = await bulkFetchOpenBD( booklist);
const fetchOthers = async ( bookInfo: BiblioInfoStatus) => {
let updatedBook = { ...bookInfo } ;
if ( ! updatedBook.isFound) {
updatedBook = await fetchNDL( updatedBook.book);
}
await sleep( randomWait( 1500 , 0.8 , 1.2 ));
if ( ! updatedBook.isFound) {
updatedBook = await fetchGoogleBooks( updatedBook.book);
}
await sleep( randomWait( 1500 , 0.8 , 1.2 ));
for ( const library of CINII_TARGETS) {
const ciniiStatus = await searchCiNii( { book: updatedBook.book, options: { libraryInfo: library } } );
if ( ciniiStatus.isOwning) {
updatedBook.book = ciniiStatus.book;
}
}
const smlStatus = searchSophiaMathLib( {
book: updatedBook.book,
options: { resources: mathLibIsbnList }
} );
if ( smlStatus.isOwning) {
updatedBook.book = smlStatus.book;
}
booklist.set( updatedBook.book.bookmeter_url, updatedBook.book);
} ;
const ps = PromiseQueue();
for ( const book of updatedBookList) {
ps.add( fetchOthers( book));
await ps.wait( 6 );
}
await ps.all();
console .log( ` ${ JOB_NAME} : Searching Completed` );
return new Map ( booklist);
} ;
3. 大学図書館 の所蔵情報を取ってくる
日本語の学術論文をネットで検索したことがある人なら、国立情報学研究所 の運営する「CiNii」というデータベースを一度は使ったことがあるでしょう。
その一部である「CiNii Books」の WebAPI を使うと、大学図書館 の蔵書を好きなクライアントから検索することができます。
support.nii.ac.jp
レスポンスがちゃんとJSON で返ってくるのは嬉しいところですが、重要な個人情報(本名・所属元)を開示しないと利用申請できないのは少しマイナスポイントかもしれません。
support.nii.ac.jp
CiNii では図書館を区別するための情報として、大学単位で割り振られる「機関ID」と、大学内にある個別の図書館施設ごとに割り振られる「図書館ID」というコードを持っています。
API を叩く際、これらの少なくとも一方を含めてリクエス トしてあげると、指定した本が狙った図書館に所蔵されているかどうかを調べることができます。
コードの一覧は、CiNii の基盤となっている「目録所在情報サービス」というシステムの公式サイトから確認できます。
contents.nii.ac.jp
contents.nii.ac.jp
なお、弊学には CiNii に情報を公開していない「数学図書室」という施設があるのですが、こちらの所蔵検索はあまり良い感じで実現できていません。
今のところ、司書さんにお願いして蔵書一覧のPDFファイルを公式サイトに掲示 してもらい(サイト容量の問題でPDFじゃないとアップロードできなかったらしい)、それをpdfdataextractというnpmパッケージで無理やりパースする形を取っています。元ファイルの問題で誤認識が多いのが目下の課題です。
github.com
ともあれ、上のような手段で大学に所蔵されている本だと分かったら、大学図書館 のOPAC リンクをCSV ファイルに出力します。
2024/01/26追記: 「CiNiiには登録されていないが、大学図書館 のOPAC 上では登録されている本」が、少なからず存在することに気づきました。一例を挙げておきます。
bookmeter.com
ci.nii.ac.jp
www.lib.sophia.ac.jp
この問題のため、CiNiiだけでは正確な所蔵情報を取ってくることができません。対策として、CiNiiの所蔵検索で見つからなかった場合は、大学図書館 のOPAC に直接アクセスしてページの実在をチェックするようにしました。
const searchCiNii: IsOwnBook< null > = async ( config: IsOwnBookConfig< null >) : Promise < BookOwningStatus> => {
const isbn = config.book[ "isbn_or_asin" ] ;
const library = config.options?.libraryInfo;
if ( library === undefined ) {
throw new Error ( "The library info is undefined" );
}
if ( isbn === null || isbn === undefined ) {
const statusText: BiblioinfoErrorStatus = "INVALID_ISBN" ;
const part = {
book_title: statusText,
author: statusText,
publisher: statusText,
published_date: statusText
} ;
return {
book: { ...config.book, ...part, [ `exist_in_ ${ library.tag} ` ] : "No" } ,
isOwning: false
} ;
}
const url = `https://ci.nii.ac.jp/books/opensearch/search?isbn= ${ isbn} &kid= ${ library?.cinii_kid} &format=json&appid= ${ cinii_appid} ` ;
const response: AxiosResponse< CiniiResponse> = await axios( {
method: "get" ,
responseType: "json" ,
url
} );
const graph = response.data[ "@graph" ][ 0 ] ;
if ( "items" in graph) {
const ncidUrl = graph.items[ 0 ][ "@id" ] ;
const ncid = ncidUrl.match( REGEX.ncid_in_cinii_url) ?.[ 0 ] ;
return {
book: {
...config.book,
[ `exist_in_ ${ library.tag} ` ] : "Yes" ,
central_opac_link: ` ${ library.opac} /opac/opac_openurl?ncid= ${ ncid} `
} ,
isOwning: true
} ;
} else {
const opacUrl = ` ${ library.opac} /opac/opac_openurl?isbn= ${ isbn} ` ;
const redirectedOpacUrl = await getRedirectedUrl( opacUrl);
await sleep( randomWait( 1000 , 0.8 , 1.2 ));
if ( redirectedOpacUrl !== undefined && redirectedOpacUrl.includes( "bibid" )) {
return {
book: {
...config.book,
[ `exist_in_ ${ library.tag} ` ] : "Yes" ,
central_opac_link: opacUrl
} ,
isOwning: true
} ;
}
return {
book: { ...config.book, [ `exist_in_ ${ library.tag} ` ] : "No" } ,
isOwning: false
} ;
}
} ;
4. デプロイして定時実行する
以下の理由から、バックエンド・フロントエンドの両方を GitHub に頼ることにしました。
人類の根源的かつ本能的な欲求として、高頻度で更新されるテキストデータの差分は Git で管理したい。
GitHub には様々な条件をきっかけに処理を自動で実行してくれる GitHub Actions という機能がある。GitHub には CSV ファイルを良い感じの表形式にレンダリング してくれる機能がある。検索機能までついている。
docs.github.com
また、単なる『読みたい本の一覧』1つだけでは情報が多すぎて小回りが効きません。
そのため「q」 というCSV 操作ツールで場合分けし、大学にある本・ない本ごとに別々のCSV ファイルを追加で作成しています。
harelba.github.io
#!/bin/bash
source_from="FROM ./bookmeter_wish_books.csv"
base_columns="isbn_or_asin, book_title, author, publisher, published_date"
filter_book_title_error="(book_title NOT LIKE 'Not_found_in%' AND book_title NOT LIKE '%INVALID_ISBN%')"
q -d, -O -H "SELECT $base_columns \
$source_from \
WHERE exist_in_Sophia='No' AND $filter_book_title_error"\
> not_in_Sophia.csv
q -d, -O -H "SELECT $base_columns, central_opac_link, mathlib_opac_link \
$source_from \
WHERE exist_in_Sophia='Yes'"\
> in_Sophia.csv
毎週日曜日の午前0時・水曜日の午後0時になると GitHub Actionsの cron 機能が発火し、これらの一連の処理を実行します。
更新されたCSV ファイルはそのまま GitHub リポジトリ にコミットされます。
出力した『読みたい本』リストを眺めてみる
現在在籍している大学と今度進学する大学院とで、どれだけ図書館の収蔵内容が違うのか見比べてみました。
まず、大学院にあって学部にない本がこちら。
github.com
ジャンルを問わず、全体的に大学院の方が蔵書がキメ細やかであることがわかります。
一方で「学部にあって大学院にない本」がこちら。
github.com
「大学の規模から言っても今の大学にしかない本なんてほとんどないだろう」と思っていましたが、意外に多くて驚きでした。全体的に、思想史(の中でもニッチな西洋神秘主義 関連の分野)・文化史・ルポルタージュ 系の本が目立ちますが、数学書 や新刊技術書でも意外と漏れがあるようです。
春休みは図書館に籠もって、このリストにある本を中心に積読 を消化していきたいと思います。
さて、現在の大学にも進学先の大学院にもない本もかなりありました。というかこれが一番多いんじゃないか?
github.com
当たり前と言えば当たり前ですが、サブカル 系の本はどちらの図書館にも所蔵されていないことが分かります。
ただ『行動経済学 の逆襲』がないのはおかしくない? ノーベル賞受賞者 の本やぞ。ISBNの問題かしら…。
あと『楽器の物理学』が今の大学にないのもおかしいって。こないだ中央図書館の9Fで見たぞ。やっぱりISBNの問題かなあ…。 ISBNの問題でした(丸善出版 の旧版とシュプリンガー・ジャパン の新版でISBNが異なっていたせいだった)。
今回の記事には間に合いませんでしたが、クラスタリング とかで読みたい本の傾向を分析してみるのも面白いかもしれません。
今後の課題
ISBNのない出版物はどうする?
以下のような本にはISBNがないため、現行のシステムでは書誌検索の対象にできません。
雑誌
80年代以前の古い本(ISBNのなかった時代の本)
Kindle 本
ASINコードとかJANコード とかの情報を使って、どうにかうまいこと書誌検索できたらいいなあと思っていますが、そもそもどこから情報を取ってこれるのか全く分かっていません。
良い感じの方法をご存じの方がいらしたら教えてください。
欲しい物が多いからには、やっぱり他人に買ってもらいたいですよね。
何とは言いませんが、ちなみに私は先月末に誕生日を迎えました。
最後に
みんなも積読 、しよう!!!
明日はstepney141さんの「このJavaScript ライブラリがキモい(褒め言葉)・2023」です。どんな記事なのか楽しみですね。